 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeENCLIP: Ensembling and Clustering-Based Contrastive Language-Image Pretraining for Fashion Multimodal Search with Limited Data and Low-Quality Images
Paper and Code
Nov 25, 2024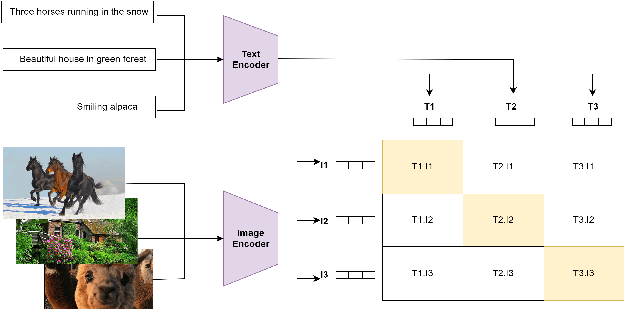

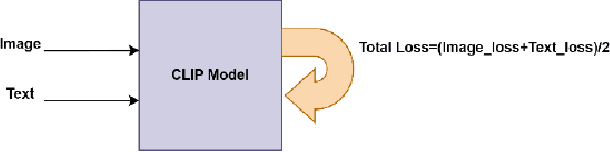

Multimodal search has revolutionized the fashion industry, providing a seamless and intuitive way for users to discover and explore fashion items. Based on their preferences, style, or specific attributes, users can search for products by combining text and image information. Text-to-image searches enable users to find visually similar items or describe products using natural language. This paper presents an innovative approach called ENCLIP, for enhancing the performance of the Contrastive Language-Image Pretraining (CLIP) model, specifically in Multimodal Search targeted towards the domain of fashion intelligence. This method focuses on addressing the challenges posed by limited data availability and low-quality images. This paper proposes an algorithm that involves training and ensembling multiple instances of the CLIP model, and leveraging clustering techniques to group similar images together. The experimental findings presented in this study provide evidence of the effectiveness of the methodology. This approach unlocks the potential of CLIP in the domain of fashion intelligence, where data scarcity and image quality issues are prevalent. Overall, the ENCLIP method represents a valuable contribution to the field of fashion intelligence and provides a practical solution for optimizing the CLIP model in scenarios with limited data and low-quality images.