 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering Dysarthric Speech: Leveraging Advanced LLMs for Accurate Speech Correction and Multimodal Emotion Analysis
Paper and Code
Oct 13, 2024

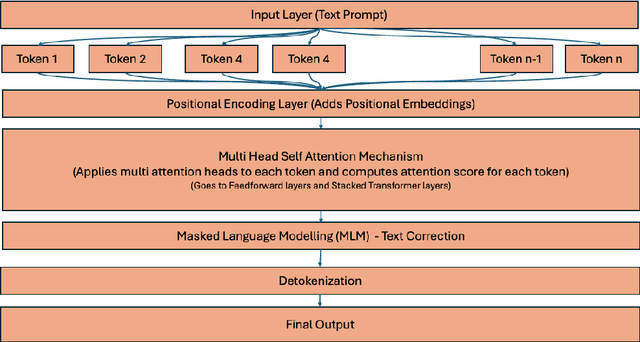

Dysarthria is a motor speech disorder caused by neurological damage that affects the muscles used for speech production, leading to slurred, slow, or difficult-to-understand speech. It affects millions of individuals worldwide, including those with conditions such as stroke, traumatic brain injury, cerebral palsy, Parkinsons disease, and multiple sclerosis. Dysarthria presents a major communication barrier, impacting quality of life and social interaction. This paper introduces a novel approach to recognizing and translating dysarthric speech, empowering individuals with this condition to communicate more effectively. We leverage advanced large language models for accurate speech correction and multimodal emotion analysis. Dysarthric speech is first converted to text using OpenAI Whisper model, followed by sentence prediction using fine-tuned open-source models and benchmark models like GPT-4.o, LLaMA 3.1 70B and Mistral 8x7B on Groq AI accelerators. The dataset used combines the TORGO dataset with Google speech data, manually labeled for emotional context. Our framework identifies emotions such as happiness, sadness, neutrality, surprise, anger, and fear, while reconstructing intended sentences from distorted speech with high accuracy. This approach demonstrates significant advancements in the recognition and interpretation of dysarthric speech.