 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElastic Gossip: Distributing Neural Network Training Using Gossip-like Protocols
Paper and Code
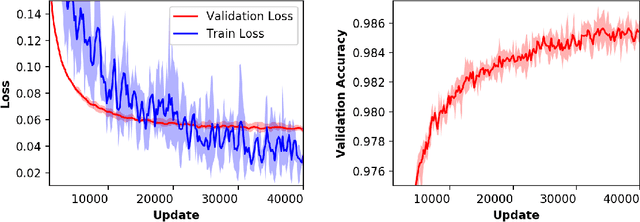

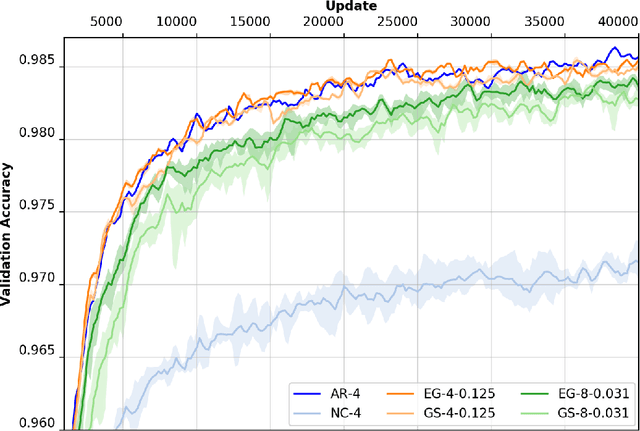

Distributing Neural Network training is of particular interest for several reasons including scaling using computing clusters, training at data sources such as IOT devices and edge servers, utilizing underutilized resources across heterogeneous environments, and so on. Most contemporary approaches primarily address scaling using computing clusters and require high network bandwidth and frequent communication. This thesis presents an overview of standard approaches to distribute training and proposes a novel technique involving pairwise-communication using Gossip-like protocols, called Elastic Gossip. This approach builds upon an existing technique known as Elastic Averaging SGD (EASGD), and is similar to another technique called Gossiping SGD which also uses Gossip-like protocols. Elastic Gossip is empirically evaluated against Gossiping SGD using the MNIST digit recognition and CIFAR-10 classification tasks, using commonly used Neural Network architectures spanning Multi-Layer Perceptrons (MLPs) and Convolutional Neural Networks (CNNs). It is found that Elastic Gossip, Gossiping SGD, and All-reduce SGD perform quite comparably, even though the latter entails a substantially higher communication cost. While Elastic Gossip performs better than Gossiping SGD in these experiments, it is possible that a more thorough search over hyper-parameter space, specific to a given application, may yield configurations of Gossiping SGD that work better than Elastic Gossip.