 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Video Generation on Complex Datasets
Paper and Code

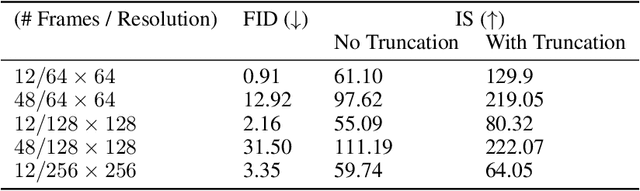

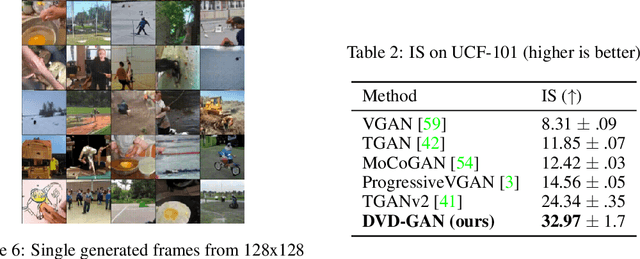
Generative models of natural images have progressed towards high fidelity samples by the strong leveraging of scale. We attempt to carry this success to the field of video modeling by showing that large Generative Adversarial Networks trained on the complex Kinetics-600 dataset are able to produce video samples of substantially higher complexity than previous work. Our proposed network, Dual Video Discriminator GAN (DVD-GAN), scales to longer and higher resolution videos by leveraging a computationally efficient decomposition of its discriminator. We evaluate on the related tasks of video synthesis and video prediction, and achieve new state of the art Frechet Inception Distance on prediction for Kinetics-600, as well as state of the art Inception Score for synthesis on the UCF-101 dataset, alongside establishing a number of strong baselines on Kinetics-600.