 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffectiveness of Vision Language Models for Open-world Single Image Test Time Adaptation
Paper and Code
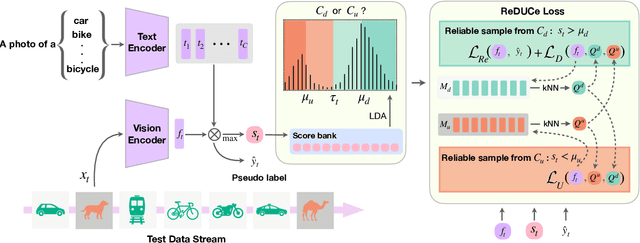
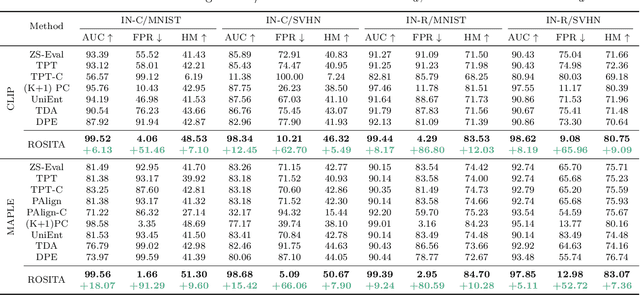
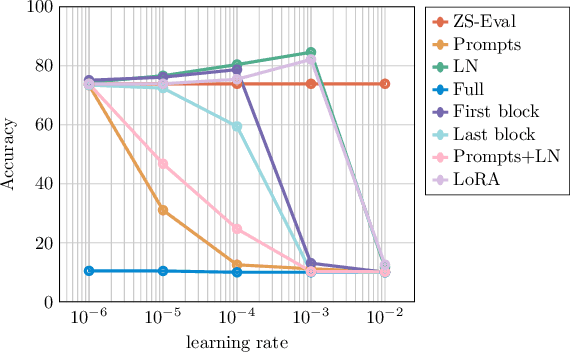
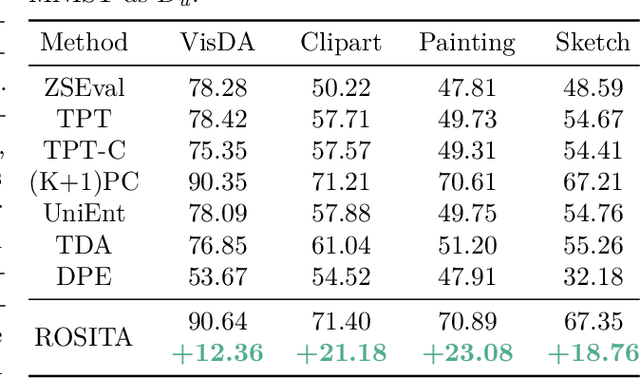
We propose a novel framework to address the real-world challenging task of Single Image Test Time Adaptation in an open and dynamic environment. We leverage large scale Vision Language Models like CLIP to enable real time adaptation on a per-image basis without access to source data or ground truth labels. Since the deployed model can also encounter unseen classes in an open world, we first employ a simple and effective Out of Distribution (OOD) detection module to distinguish between weak and strong OOD samples. We propose a novel contrastive learning based objective to enhance the discriminability between weak and strong OOD samples by utilizing small, dynamically updated feature banks. Finally, we also employ a classification objective for adapting the model using the reliable weak OOD samples. The proposed framework ROSITA combines these components, enabling continuous online adaptation of Vision Language Models on a single image basis. Extensive experimentation on diverse domain adaptation benchmarks validates the effectiveness of the proposed framework. Our code can be found at the project site https://manogna-s.github.io/rosita/