 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Attention Sheds Light On Interpretability
Paper and Code

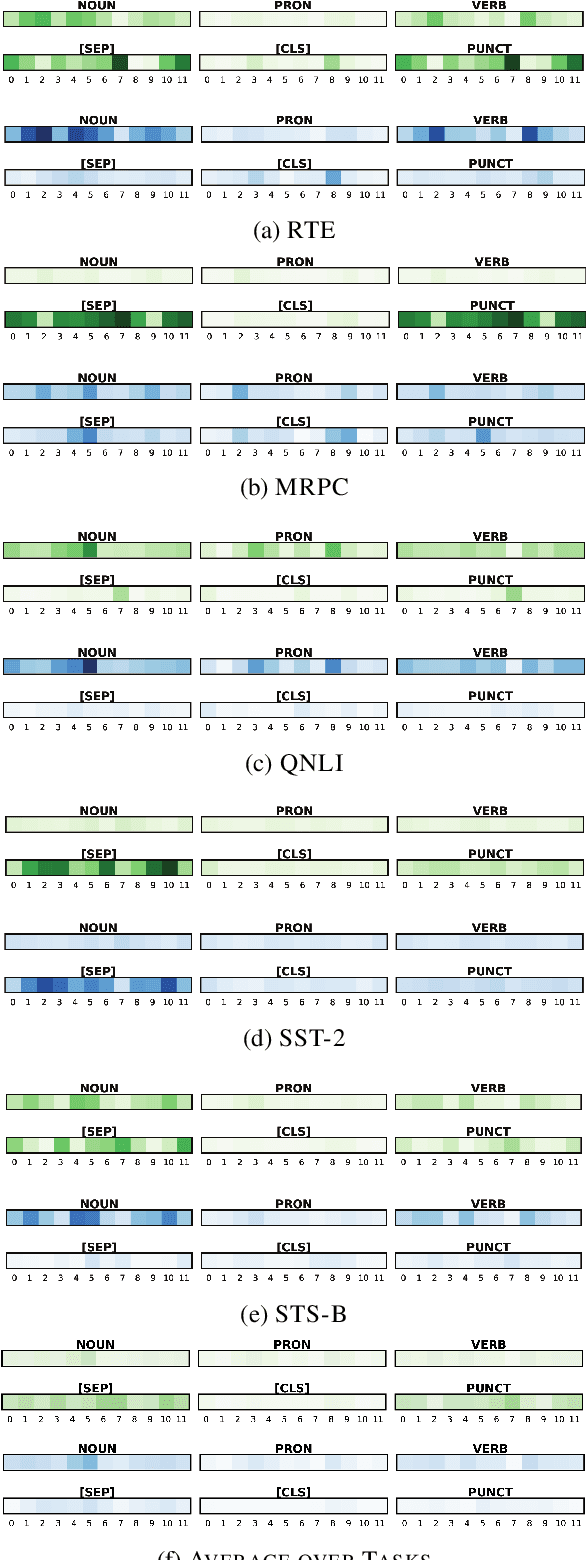
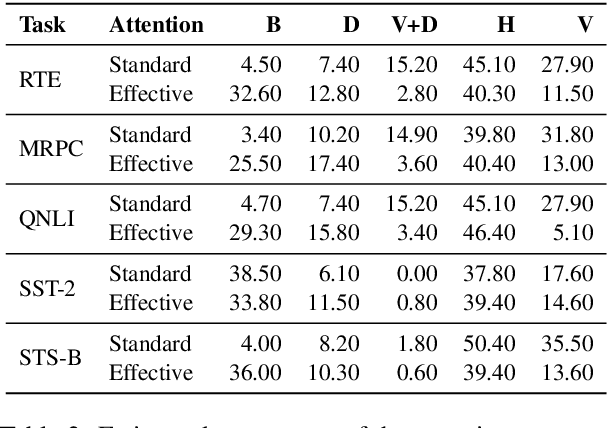
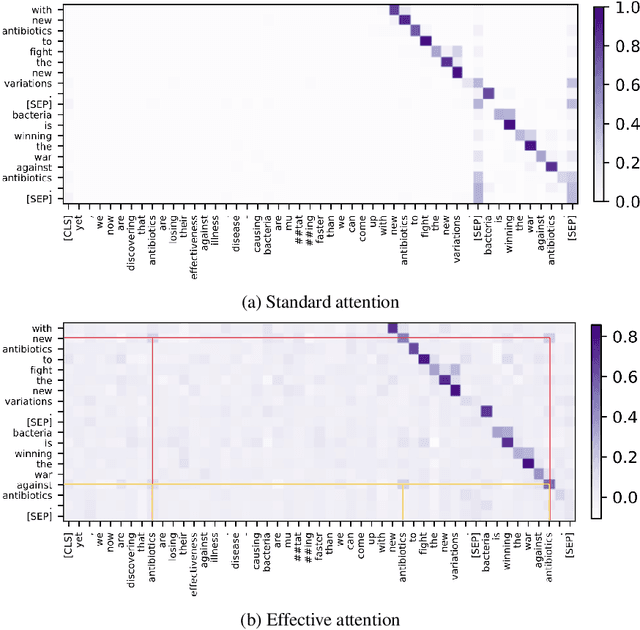
An attention matrix of a transformer self-attention sublayer can provably be decomposed into two components and only one of them (effective attention) contributes to the model output. This leads us to ask whether visualizing effective attention gives different conclusions than interpretation of standard attention. Using a subset of the GLUE tasks and BERT, we carry out an analysis to compare the two attention matrices, and show that their interpretations differ. Effective attention is less associated with the features related to the language modeling pretraining such as the separator token, and it has more potential to illustrate linguistic features captured by the model for solving the end-task. Given the found differences, we recommend using effective attention for studying a transformer's behavior since it is more pertinent to the model output by design.