 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdinburghNLP at WNUT-2020 Task 2: Leveraging Transformers with Generalized Augmentation for Identifying Informativeness in COVID-19 Tweets
Paper and Code

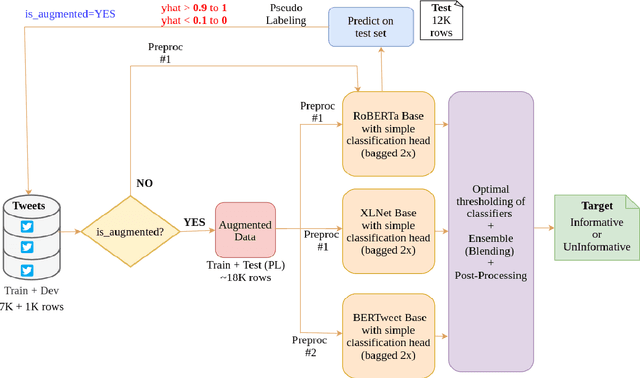
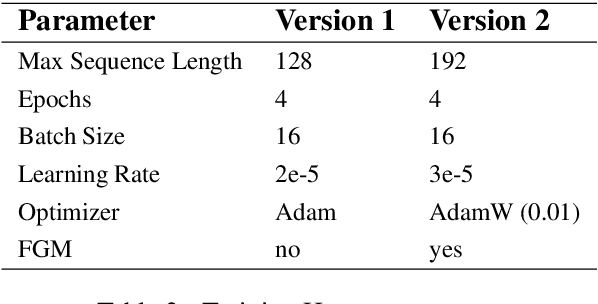
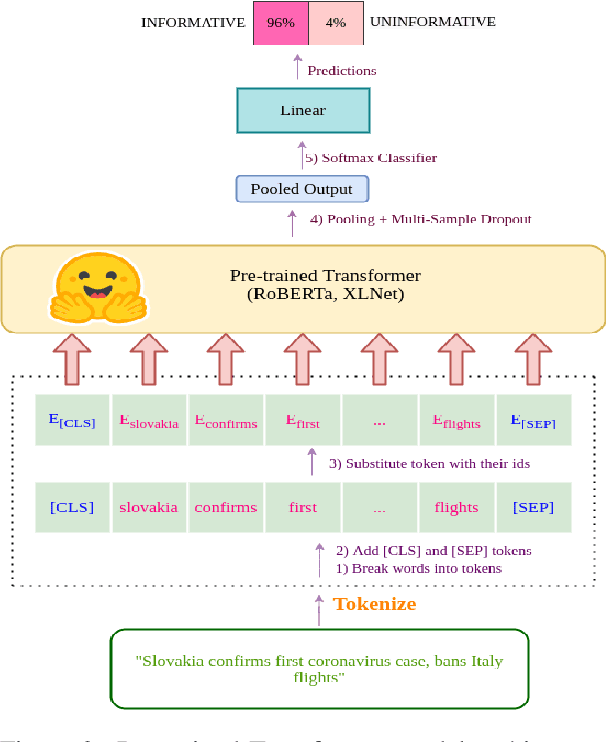
Twitter has become an important communication channel in times of emergency. The ubiquitousness of smartphones enables people to announce an emergency they're observing in real-time. Because of this, more agencies are interested in programatically monitoring Twitter (disaster relief organizations and news agencies) and therefore recognizing the informativeness of a tweet can help filter noise from large volumes of data. In this paper, we present our submission for WNUT-2020 Task 2: Identification of informative COVID-19 English Tweets. Our most successful model is an ensemble of transformers including RoBERTa, XLNet, and BERTweet trained in a semi-supervised experimental setting. The proposed system achieves a F1 score of 0.9011 on the test set (ranking 7th on the leaderboard), and shows significant gains in performance compared to a baseline system using fasttext embeddings.