 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Gesture Recognition
Paper and Code
Sep 29, 2021

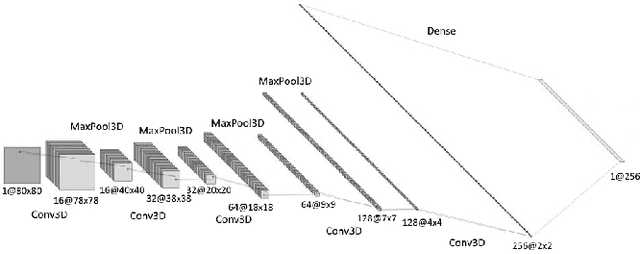
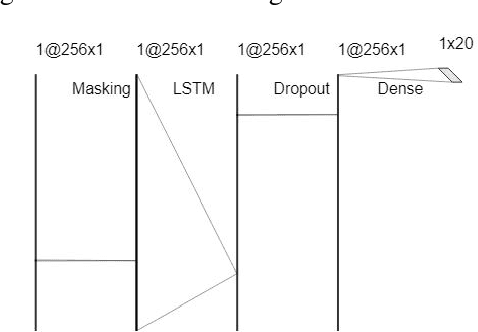
The Human-Machine Interaction (HMI) research field is an important topic in machine learning that has been deeply investigated thanks to the rise of computing power in the last years. The first time, it is possible to use machine learning to classify images and/or videos instead of the traditional computer vision algorithms. The aim of this paper is to build a symbiosis between a convolutional neural network (CNN) and a recurrent neural network (RNN) to recognize cultural/anthropological Italian sign language gestures from videos. The CNN extracts important features that later are used by the RNN. With RNNs we are able to store temporal information inside the model to provide contextual information from previous frames to enhance the prediction accuracy. Our novel approach uses different data augmentation techniques and regularization methods from only RGB frames to avoid overfitting and provide a small generalization error.