 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDropIT: Dropping Intermediate Tensors for Memory-Efficient DNN Training
Paper and Code
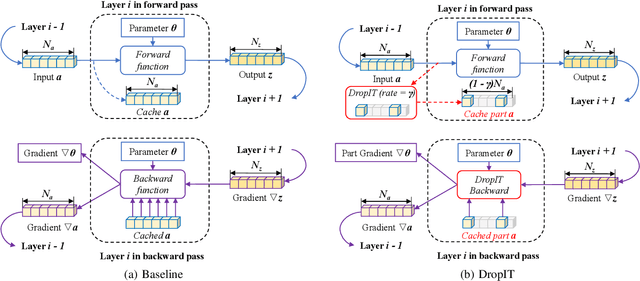
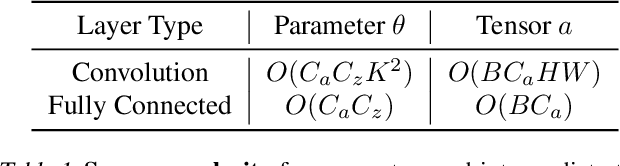
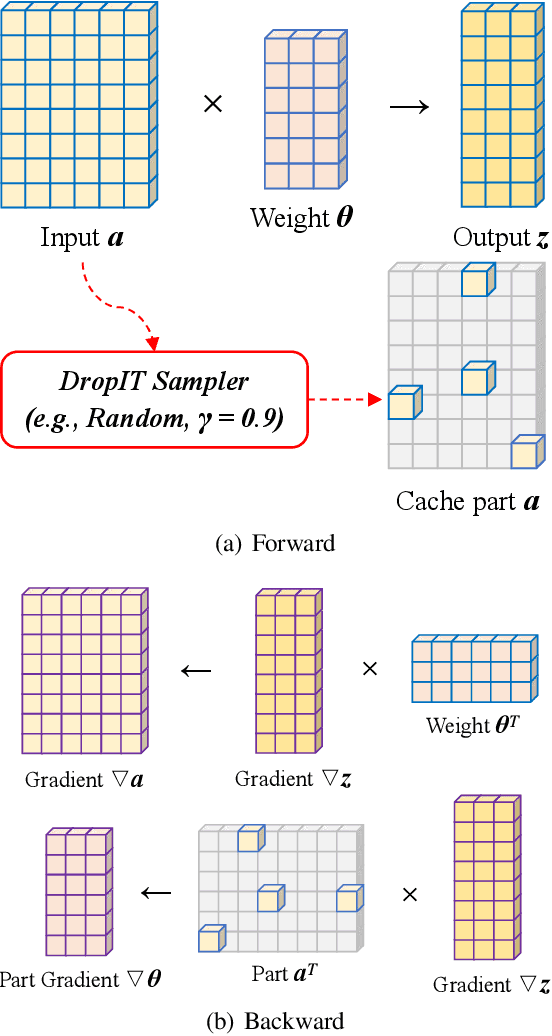
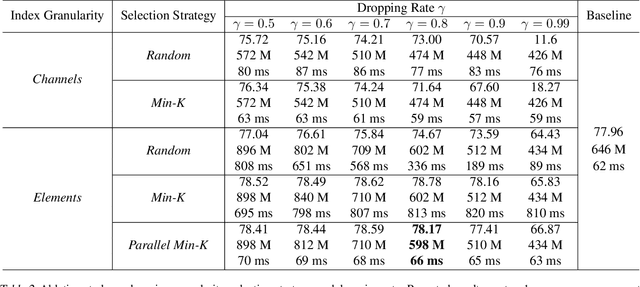
A standard hardware bottleneck when training deep neural networks is GPU memory. The bulk of memory is occupied by caching intermediate tensors for gradient computation in the backward pass. We propose a novel method to reduce this footprint by selecting and caching part of intermediate tensors for gradient computation. Our Intermediate Tensor Drop method (DropIT) adaptively drops components of the intermediate tensors and recovers sparsified tensors from the remaining elements in the backward pass to compute the gradient. Experiments show that we can drop up to 90% of the elements of the intermediate tensors in convolutional and fully-connected layers, saving 20% GPU memory during training while achieving higher test accuracy for standard backbones such as ResNet and Vision Transformer. Our code is available at https://github.com/ChenJoya/dropit.