 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamNLP: Novel NLP System for Clinical Report Metadata Extraction using Count Sketch Data Streaming Algorithm: Preliminary Results
Paper and Code
Aug 26, 2018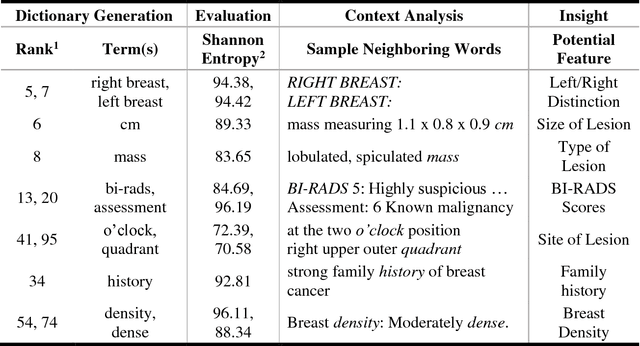
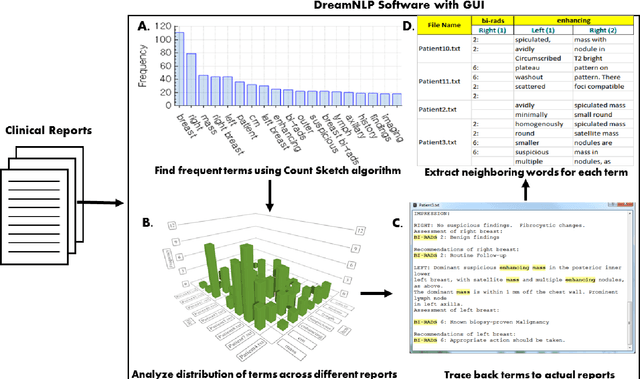

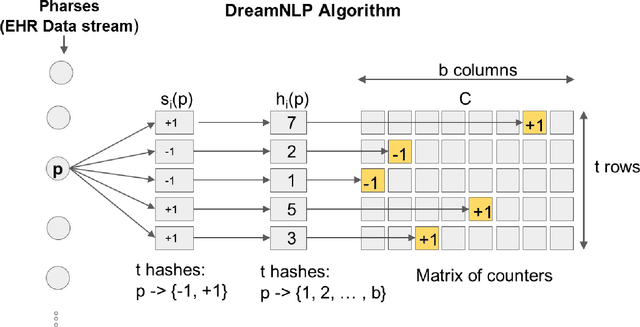
Extracting information from electronic health records (EHR) is a challenging task since it requires prior knowledge of the reports and some natural language processing algorithm (NLP). With the growing number of EHR implementations, such knowledge is increasingly challenging to obtain in an efficient manner. We address this challenge by proposing a novel methodology to analyze large sets of EHRs using a modified Count Sketch data streaming algorithm termed DreamNLP. By using DreamNLP, we generate a dictionary of frequently occurring terms or heavy hitters in the EHRs using low computational memory compared to conventional counting approach other NLP programs use. We demonstrate the extraction of the most important breast diagnosis features from the EHRs in a set of patients that underwent breast imaging. Based on the analysis, extraction of these terms would be useful for defining important features for downstream tasks such as machine learning for precision medicine.