Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocument summarization using positive pointwise mutual information
Paper and Code
May 08, 2012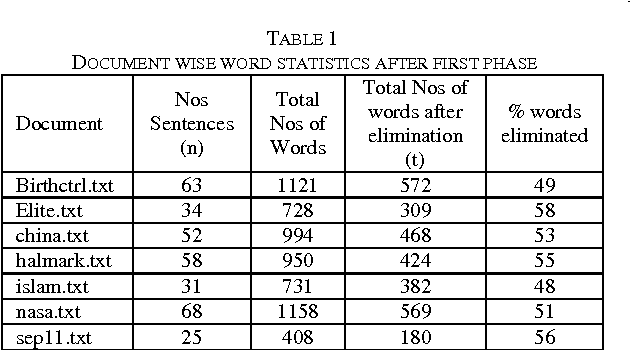
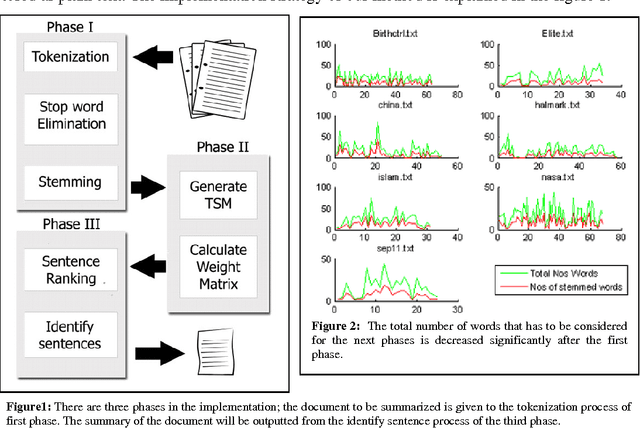
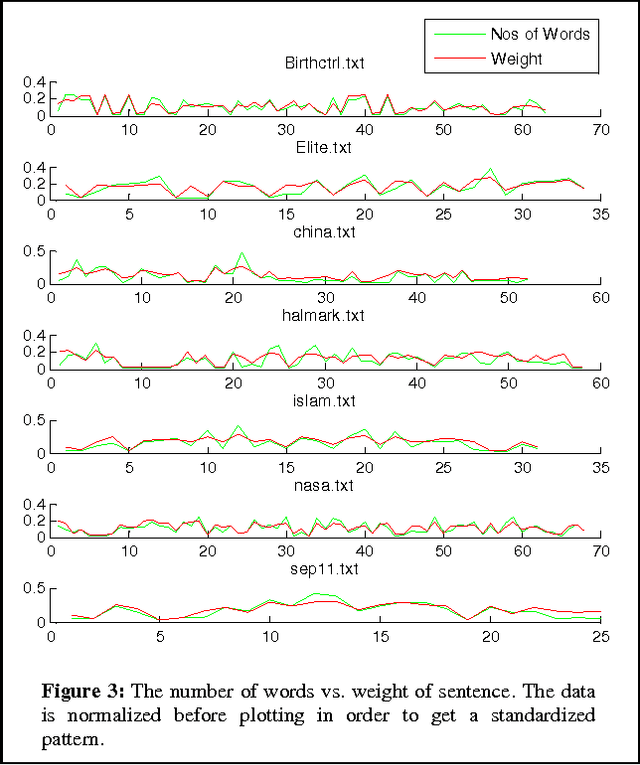
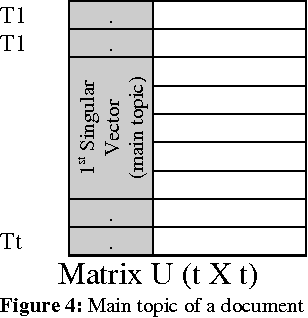
The degree of success in document summarization processes depends on the performance of the method used in identifying significant sentences in the documents. The collection of unique words characterizes the major signature of the document, and forms the basis for Term-Sentence-Matrix (TSM). The Positive Pointwise Mutual Information, which works well for measuring semantic similarity in the Term-Sentence-Matrix, is used in our method to assign weights for each entry in the Term-Sentence-Matrix. The Sentence-Rank-Matrix generated from this weighted TSM, is then used to extract a summary from the document. Our experiments show that such a method would outperform most of the existing methods in producing summaries from large documents.
View paper on