Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo you MIND? Reflections on the MIND dataset for research on diversity in news recommendations
Paper and Code

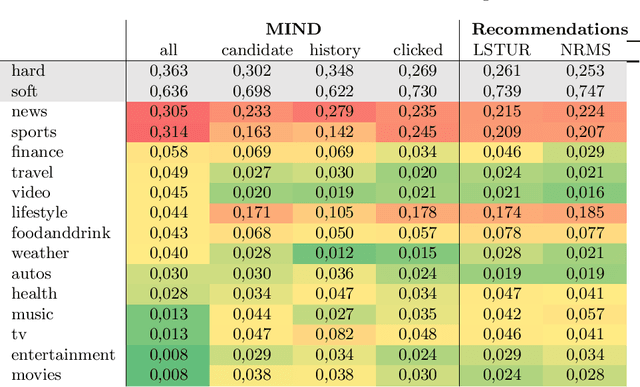
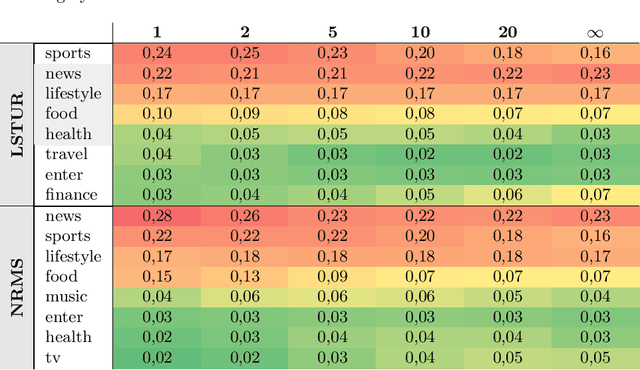
The MIND dataset is at the moment of writing the most extensive dataset available for the research and development of news recommender systems. This work analyzes the suitability of the dataset for research on diverse news recommendations. On the one hand we analyze the effect the different steps in the recommendation pipeline have on the distribution of article categories, and on the other hand we check whether the supplied data would be sufficient for more sophisticated diversity analysis. We conclude that while MIND is a great step forward, there is still a lot of room for improvement.
View paper on