 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Discrete Self-Supervised Representations of Speech Capture Tone Distinctions?
Paper and Code
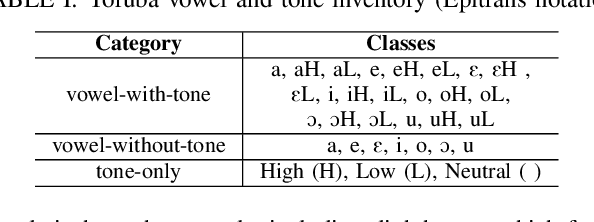
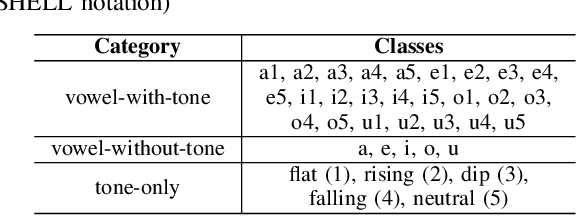

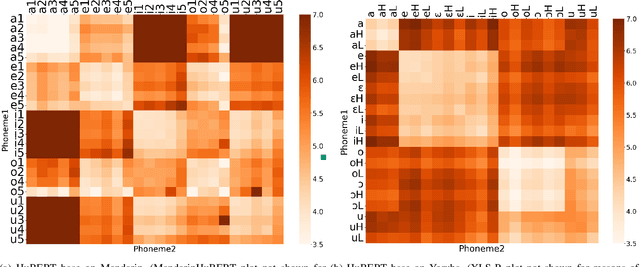
Discrete representations of speech, obtained from Self-Supervised Learning (SSL) foundation models, are widely used, especially where there are limited data for the downstream task, such as for a low-resource language. Typically, discretization of speech into a sequence of symbols is achieved by unsupervised clustering of the latents from an SSL model. Our study evaluates whether discrete symbols - found using k-means - adequately capture tone in two example languages, Mandarin and Yoruba. We compare latent vectors with discrete symbols, obtained from HuBERT base, MandarinHuBERT, or XLS-R, for vowel and tone classification. We find that using discrete symbols leads to a substantial loss of tone information, even for language-specialised SSL models. We suggest that discretization needs to be task-aware, particularly for tone-dependent downstream tasks.