 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiviML: A Module-based Heuristic for Mapping Neural Networks onto Heterogeneous Platforms
Paper and Code
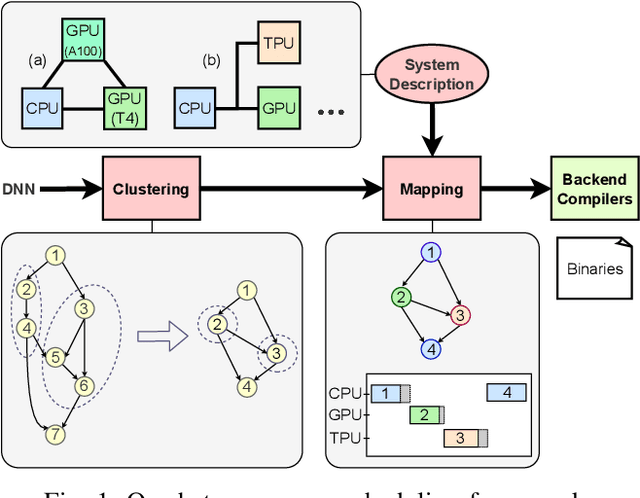
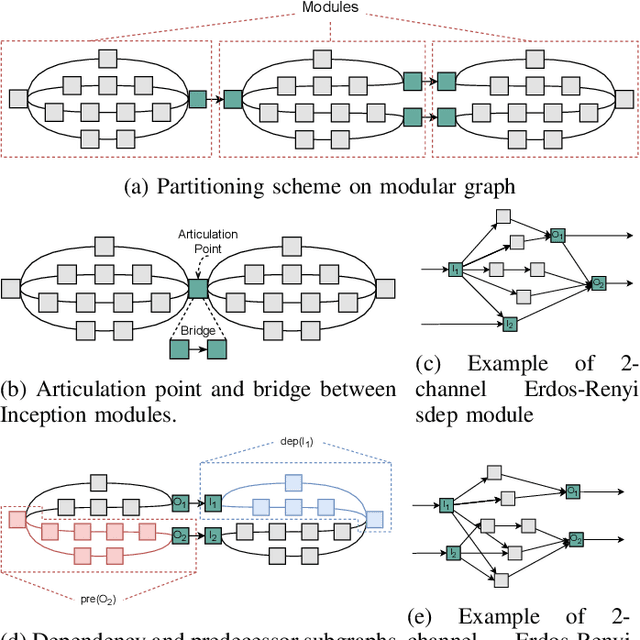
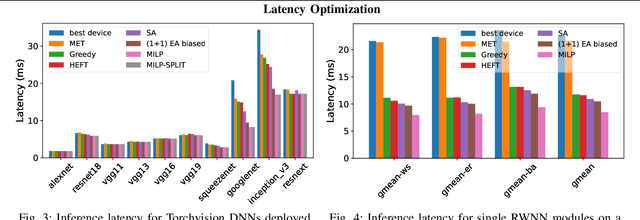
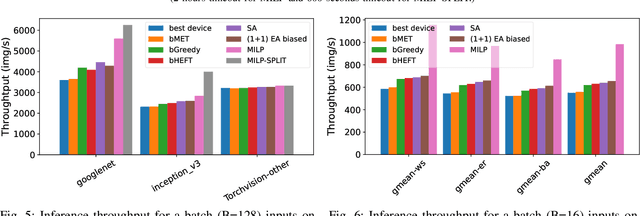
Datacenters are increasingly becoming heterogeneous, and are starting to include specialized hardware for networking, video processing, and especially deep learning. To leverage the heterogeneous compute capability of modern datacenters, we develop an approach for compiler-level partitioning of deep neural networks (DNNs) onto multiple interconnected hardware devices. We present a general framework for heterogeneous DNN compilation, offering automatic partitioning and device mapping. Our scheduler integrates both an exact solver, through a mixed integer linear programming (MILP) formulation, and a modularity-based heuristic for scalability. Furthermore, we propose a theoretical lower bound formula for the optimal solution, which enables the assessment of the heuristic solutions' quality. We evaluate our scheduler in optimizing both conventional DNNs and randomly-wired neural networks, subject to latency and throughput constraints, on a heterogeneous system comprised of a CPU and two distinct GPUs. Compared to na\"ively running DNNs on the fastest GPU, he proposed framework can achieve more than 3$\times$ times lower latency and up to 2.9$\times$ higher throughput by automatically leveraging both data and model parallelism to deploy DNNs on our sample heterogeneous server node. Moreover, our modularity-based "splitting" heuristic improves the solution runtime up to 395$\times$ without noticeably sacrificing solution quality compared to an exact MILP solution, and outperforms all other heuristics by 30-60% solution quality. Finally, our case study shows how we can extend our framework to schedule large language models across multiple heterogeneous servers by exploiting symmetry in the hardware setup. Our code can be easily plugged in to existing frameworks, and is available at https://github.com/abdelfattah-lab/diviml.