 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Variational Information Bottleneck for Multiview Representation Learning
Paper and Code
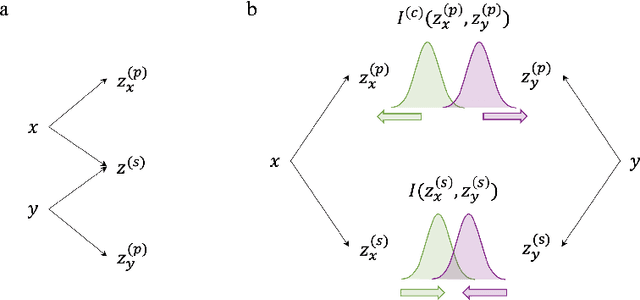

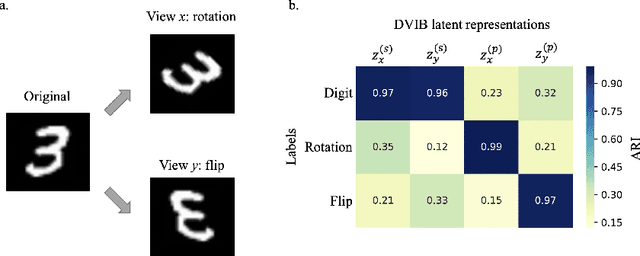
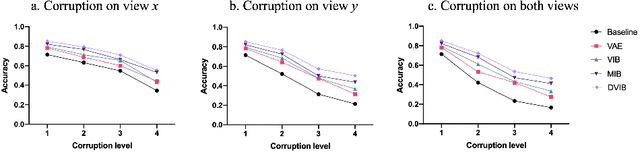
Multiview data contain information from multiple modalities and have potentials to provide more comprehensive features for diverse machine learning tasks. A fundamental question in multiview analysis is what is the additional information brought by additional views and can quantitatively identify this additional information. In this work, we try to tackle this challenge by decomposing the entangled multiview features into shared latent representations that are common across all views and private representations that are specific to each single view. We formulate this feature disentanglement in the framework of information bottleneck and propose disentangled variational information bottleneck (DVIB). DVIB explicitly defines the properties of shared and private representations using constrains from mutual information. By deriving variational upper and lower bounds of mutual information terms, representations are efficiently optimized. We demonstrate the shared and private representations learned by DVIB well preserve the common labels shared between two views and unique labels corresponding to each single view, respectively. DVIB also shows comparable performance in classification task on images with corruptions. DVIB implementation is available at https://github.com/feng-bao-ucsf/DVIB.