 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovery of a missing disease spreader
Paper and Code
Jun 09, 2011

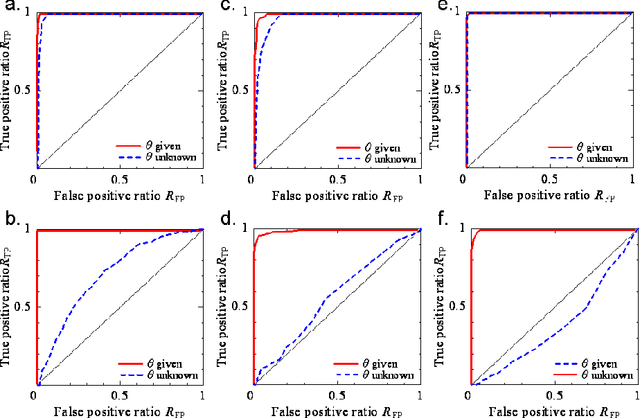

This study presents a method to discover an outbreak of an infectious disease in a region for which data are missing, but which is at work as a disease spreader. Node discovery for the spread of an infectious disease is defined as discriminating between the nodes which are neighboring to a missing disease spreader node, and the rest, given a dataset on the number of cases. The spread is described by stochastic differential equations. A perturbation theory quantifies the impact of the missing spreader on the moments of the number of cases. Statistical discriminators examine the mid-body or tail-ends of the probability density function, and search for the disturbance from the missing spreader. They are tested with computationally synthesized datasets, and applied to the SARS outbreak and flu pandemic.