 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscourse structure interacts with reference but not syntax in neural language models
Paper and Code
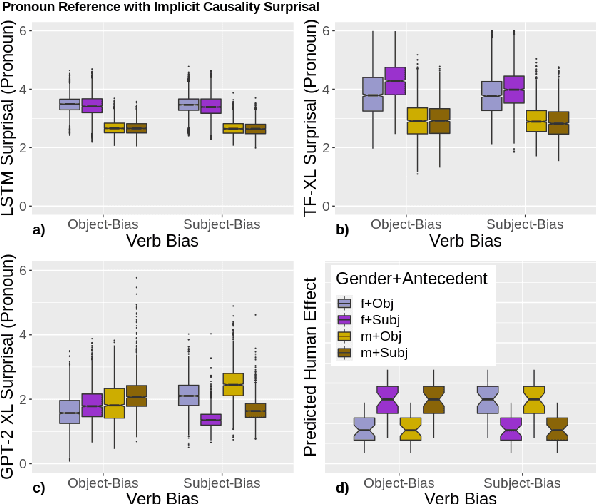
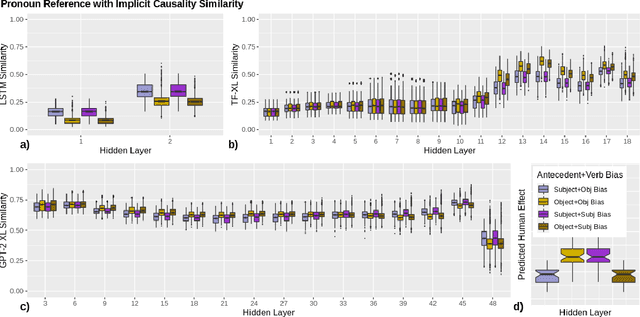


Language models (LMs) trained on large quantities of text have been claimed to acquire abstract linguistic representations. Our work tests the robustness of these abstractions by focusing on the ability of LMs to learn interactions between different linguistic representations. In particular, we utilized stimuli from psycholinguistic studies showing that humans can condition reference (i.e. coreference resolution) and syntactic processing on the same discourse structure (implicit causality). We compared both transformer and long short-term memory LMs to find that, contrary to humans, implicit causality only influences LM behavior for reference, not syntax, despite model representations that encode the necessary discourse information. Our results further suggest that LM behavior can contradict not only learned representations of discourse but also syntactic agreement, pointing to shortcomings of standard language modeling.