 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgedisco: a toolkit for Distributional Control of Generative Models
Paper and Code
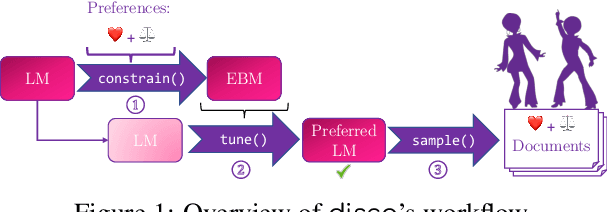
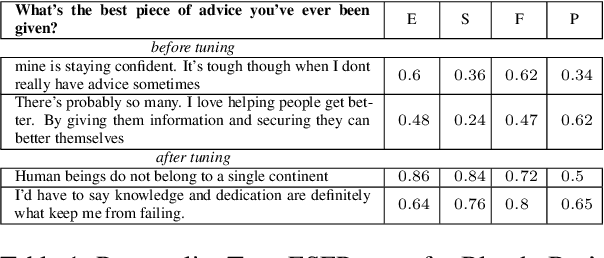
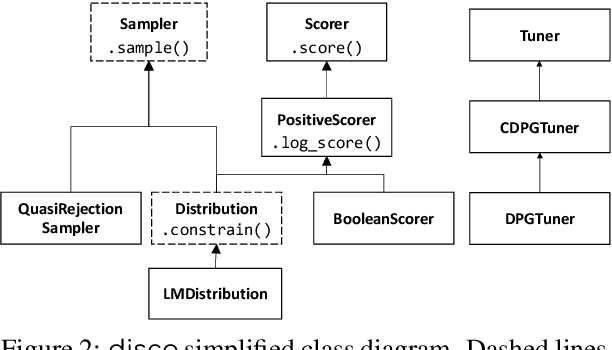
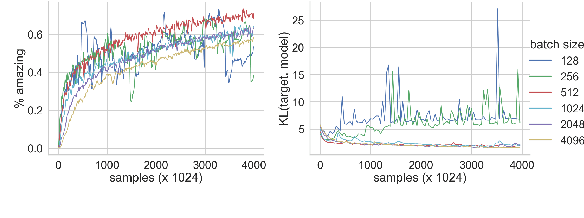
Pre-trained language models and other generative models have revolutionized NLP and beyond. However, these models tend to reproduce undesirable biases present in their training data. Also, they may overlook patterns that are important but challenging to capture. To address these limitations, researchers have introduced distributional control techniques. These techniques, not limited to language, allow controlling the prevalence (i.e., expectations) of any features of interest in the model's outputs. Despite their potential, the widespread adoption of these techniques has been hindered by the difficulty in adapting complex, disconnected code. Here, we present disco, an open-source Python library that brings these techniques to the broader public.