 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Approximation Bridges For Training Networks Containing Non-Differentiable Functions
Paper and Code
May 09, 2019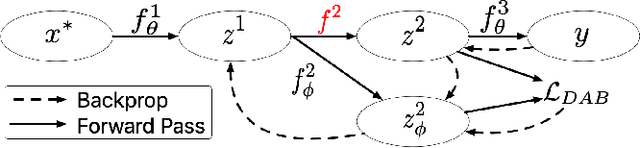

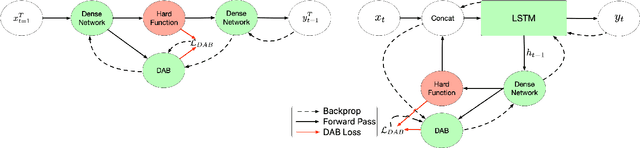

Modern neural network training relies on piece-wise (sub-)differentiable functions in order to use backpropation for efficient calculation of gradients. In this work, we introduce a novel method to allow for non-differentiable functions at intermediary layers of deep neural networks. We do so through the introduction of a differentiable approximation bridge (DAB) neural network which provides smooth approximations to the gradient of the non-differentiable function. We present strong empirical results (performing over 600 experiments) in three different domains: unsupervised (image) representation learning, image classification, and sequence sorting to demonstrate that our proposed method improves state of the art performance. We demonstrate that utilizing non-differentiable functions in unsupervised (image) representation learning improves reconstruction quality and posterior linear separability by 10%. We also observe an accuracy improvement of 77% in neural sequence sorting and a 25% improvement against the straight-through estimator [3] in an image classification setting with the sort non-linearity. This work enables the usage of functions that were previously not usable in neural networks.