 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexVIP: Learning Dexterous Grasping with Human Hand Pose Priors from Video
Paper and Code
Feb 01, 2022
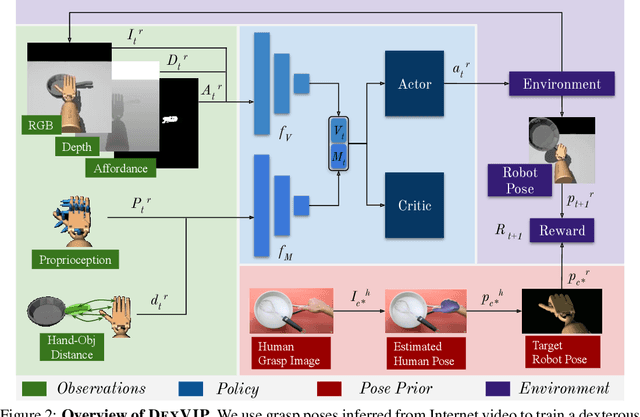

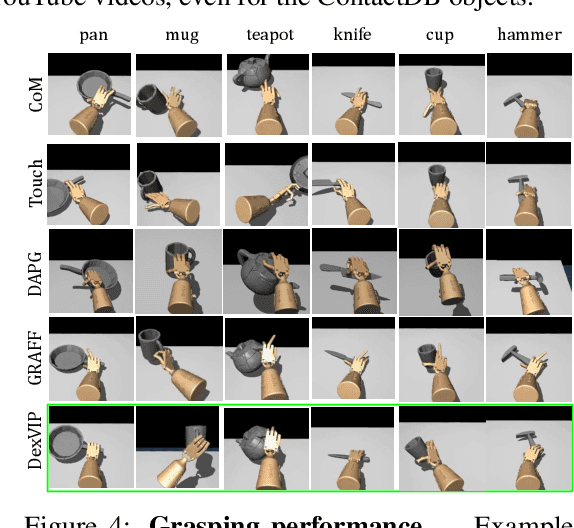
Dexterous multi-fingered robotic hands have a formidable action space, yet their morphological similarity to the human hand holds immense potential to accelerate robot learning. We propose DexVIP, an approach to learn dexterous robotic grasping from human-object interactions present in in-the-wild YouTube videos. We do this by curating grasp images from human-object interaction videos and imposing a prior over the agent's hand pose when learning to grasp with deep reinforcement learning. A key advantage of our method is that the learned policy is able to leverage free-form in-the-wild visual data. As a result, it can easily scale to new objects, and it sidesteps the standard practice of collecting human demonstrations in a lab -- a much more expensive and indirect way to capture human expertise. Through experiments on 27 objects with a 30-DoF simulated robot hand, we demonstrate that DexVIP compares favorably to existing approaches that lack a hand pose prior or rely on specialized tele-operation equipment to obtain human demonstrations, while also being faster to train. Project page: https://vision.cs.utexas.edu/projects/dexvip-dexterous-grasp-pose-prior