 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping an efficient corpus using Ensemble Data cleaning approach
Paper and Code
Jun 02, 2024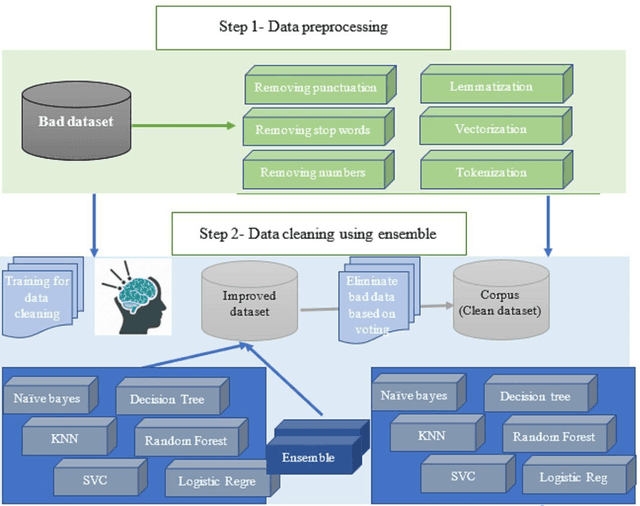

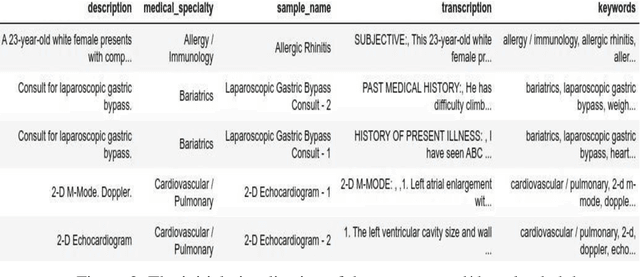

Despite the observable benefit of Natural Language Processing (NLP) in processing a large amount of textual medical data within a limited time for information retrieval, a handful of research efforts have been devoted to uncovering novel data-cleaning methods. Data cleaning in NLP is at the centre point for extracting validated information. Another observed limitation in the NLP domain is having limited medical corpora that provide answers to a given medical question. Realising the limitations and challenges from two perspectives, this research aims to clean a medical dataset using ensemble techniques and to develop a corpus. The corpora expect that it will answer the question based on the semantic relationship of corpus sequences. However, the data cleaning method in this research suggests that the ensemble technique provides the highest accuracy (94%) compared to the single process, which includes vectorisation, exploratory data analysis, and feeding the vectorised data. The second aim of having an adequate corpus was realised by extracting answers from the dataset. This research is significant in machine learning, specifically data cleaning and the medical sector, but it also underscores the importance of NLP in the medical field, where accurate and timely information extraction can be a matter of life and death. It establishes text data processing using NLP as a powerful tool for extracting valuable information like image data.