 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection and Recovery of Adversarial Attacks with Injected Attractors
Paper and Code
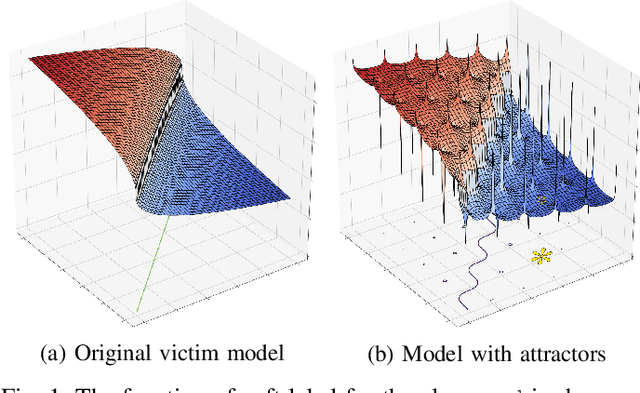
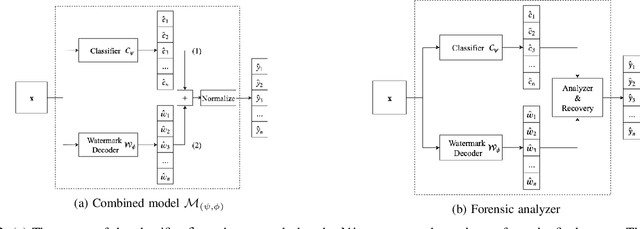
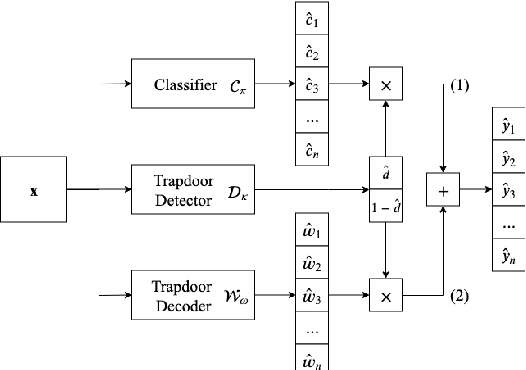
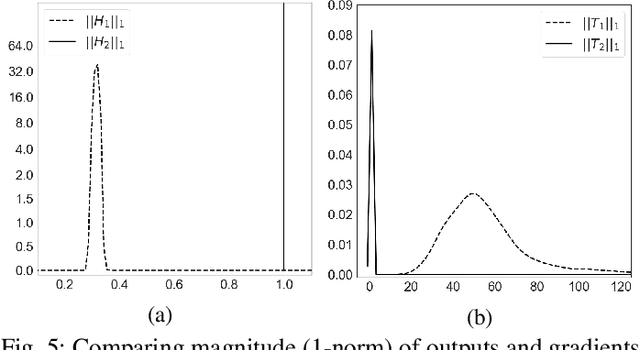
Many machine learning adversarial attacks find adversarial samples of a victim model ${\mathcal M}$ by following the gradient of some functions, either explicitly or implicitly. To detect and recover from such attacks, we take the proactive approach that modifies those functions with the goal of misleading the attacks to some local minimals, or to some designated regions that can be easily picked up by a forensic analyzer. To achieve the goal, we propose adding a large number of artifacts, which we called $attractors$, onto the otherwise smooth function. An attractor is a point in the input space, which has a neighborhood of samples with gradients pointing toward it. We observe that decoders of watermarking schemes exhibit properties of attractors, and give a generic method that injects attractors from a watermark decoder into the victim model ${\mathcal M}$. This principled approach allows us to leverage on known watermarking schemes for scalability and robustness. Experimental studies show that our method has competitive performance. For instance, for un-targeted attacks on CIFAR-10 dataset, we can reduce the overall attack success rate of DeepFool to 1.9%, whereas known defence LID, FS and MagNet can reduce the rate to 90.8%, 98.5% and 78.5% respectively.