Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Sub-Topic Correspondence through Bipartite Term Clustering
Paper and Code
Aug 01, 1999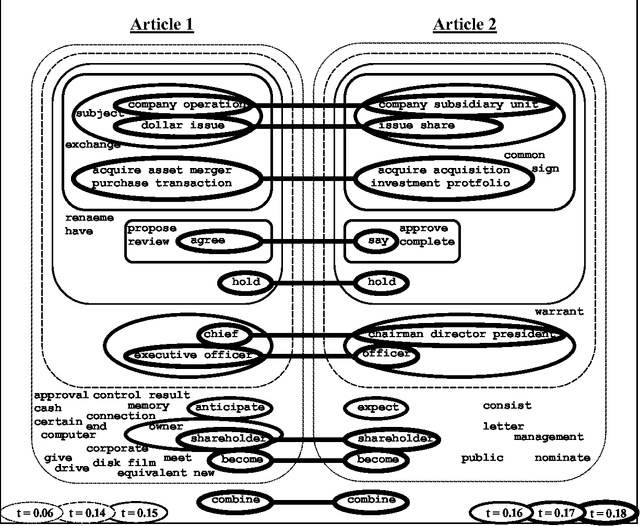
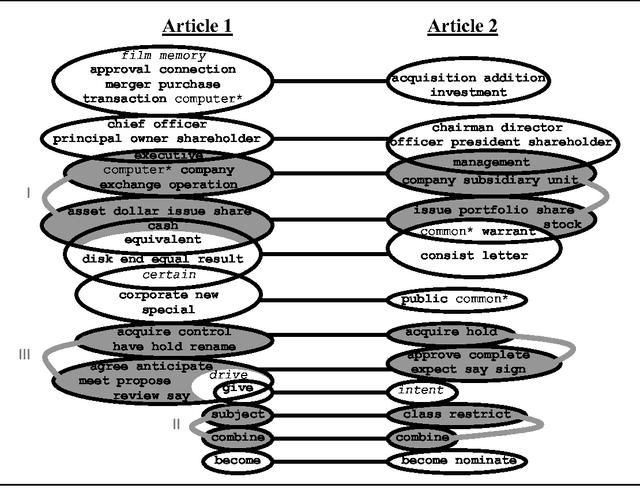
This paper addresses a novel task of detecting sub-topic correspondence in a pair of text fragments, enhancing common notions of text similarity. This task is addressed by coupling corresponding term subsets through bipartite clustering. The paper presents a cost-based clustering scheme and compares it with a bipartite version of the single-link method, providing illustrating results.
* Proceedings of ACL'99 Workshop on Unsupervised Learning in Natural
Language Processing, 1999, pp 45-51 * html with 3 gif figures; generated from 7 pages MS-Word file
View paper on