 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Anomalous Invoice Line Items in the Legal Case Lifecycle
Paper and Code
Jan 17, 2021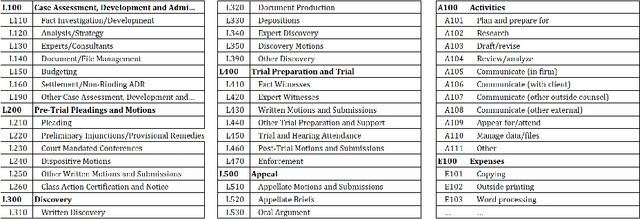
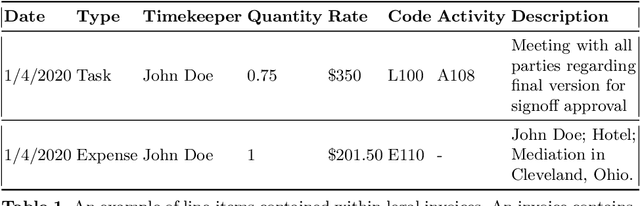
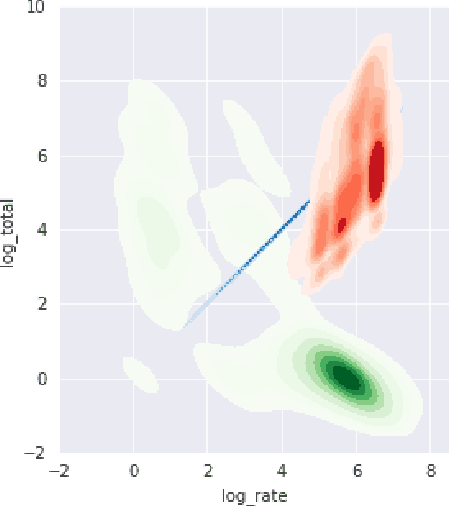
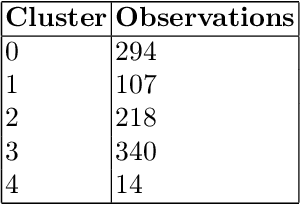
The United States is the largest distributor of legal services in the world, representing a \$437 billion market. Of this, corporate legal departments pay law firms \$80 billion for their services. Every month, legal departments receive and process invoices from these law firms and legal service providers. Legal invoice review is and has been a pain point for corporate legal department leaders. Complex and intricate, legal invoices often contain several hundred line-items that account for anything from tasks such as hands-on legal work to expenses such as copying, meals, and travel. The man-hours and scrutiny involved in the invoice review process can be overwhelming. Even with common safeguards in place, such as established billing guidelines, experienced invoice reviewers (typically highly paid in-house attorneys), and rule based electronic billing tools ("e-billing"), many discrepancies go undetected. Using machine learning, our goal is to demonstrate the current flaws of, and to explore improvements to, the legal invoice review process for invoices submitted by law firms to their corporate clients. In this work, we detail our approach, applying several machine learning model architectures, for detecting anomalous invoice line-items based on their suitability in the legal case's lifecycle (modeled using a set of case level and invoice line-item-level features). We illustrate our approach, which works in the absence of labeled data, by utilizing a combination of subject matter expertise ("SME") and synthetic data generation for model training. We characterize our method's performance using a set of model architectures. We demonstrate how this process advances solving anomaly detection problems, specifically when the characteristics of the anomalies are well known, and offer lessons learned from applying our approach to real-world data.