 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetect Only What You Specify : Object Detection with Linguistic Target
Paper and Code
Nov 18, 2022

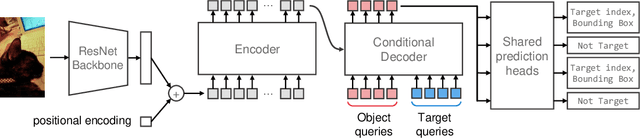

Object detection is a computer vision task of predicting a set of bounding boxes and category labels for each object of interest in a given image. The category is related to a linguistic symbol such as 'dog' or 'person' and there should be relationships among them. However the object detector only learns to classify the categories and does not treat them as the linguistic symbols. Multi-modal models often use the pre-trained object detector to extract object features from the image, but the models are separated from the detector and the extracted visual features does not change with their linguistic input. We rethink the object detection as a vision-and-language reasoning task. We then propose targeted detection task, where detection targets are given by a natural language and the goal of the task is to detect only all the target objects in a given image. There are no detection if the target is not given. Commonly used modern object detectors have many hand-designed components like anchor and it is difficult to fuse the textual inputs into the complex pipeline. We thus propose Language-Targeted Detector (LTD) for the targeted detection based on a recently proposed Transformer-based detector. LTD is a encoder-decoder architecture and our conditional decoder allows the model to reason about the encoded image with the textual input as the linguistic context. We evaluate detection performances of LTD on COCO object detection dataset and also show that our model improves the detection results with the textual input grounding to the visual object.