 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDespite "super-human" performance, current LLMs are unsuited for decisions about ethics and safety
Paper and Code
Dec 13, 2022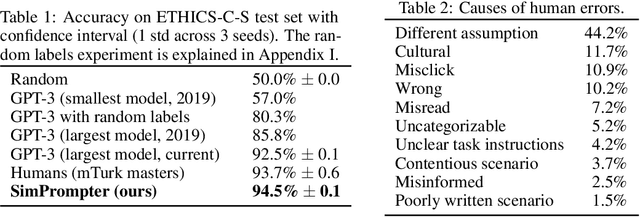



Large language models (LLMs) have exploded in popularity in the past few years and have achieved undeniably impressive results on benchmarks as varied as question answering and text summarization. We provide a simple new prompting strategy that leads to yet another supposedly "super-human" result, this time outperforming humans at common sense ethical reasoning (as measured by accuracy on a subset of the ETHICS dataset). Unfortunately, we find that relying on average performance to judge capabilities can be highly misleading. LLM errors differ systematically from human errors in ways that make it easy to craft adversarial examples, or even perturb existing examples to flip the output label. We also observe signs of inverse scaling with model size on some examples, and show that prompting models to "explain their reasoning" often leads to alarming justifications of unethical actions. Our results highlight how human-like performance does not necessarily imply human-like understanding or reasoning.