 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign a Delicious Lunchbox in Style
Paper and Code
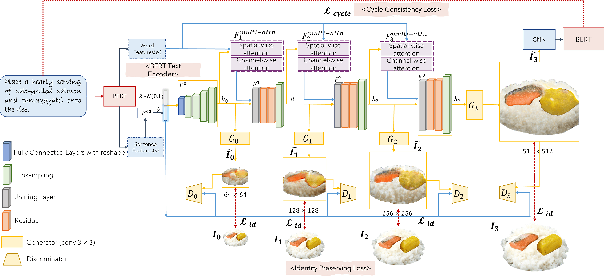



We propose a cyclic generative adversarial network with spatial-wise and channel-wise attention modules for text-to-image synthesis. To accurately depict and design scenes with multiple occluded objects, we design a pre-trained ordering recovery model and a generative adversarial network to predict layout and composite novel box lunch presentations. In the experiments, we devise the Bento800 dataset to evaluate the performance of the text-to-image synthesis model and the layout generation & image composition model. This paper is the continuation of our previous paper works. We also present additional experiments and qualitative performance comparisons to verify the effectiveness of our proposed method. Bento800 dataset is available at https://github.com/Yutong-Zhou-cv/Bento800_Dataset