 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenseCLIP: Extract Free Dense Labels from CLIP
Paper and Code
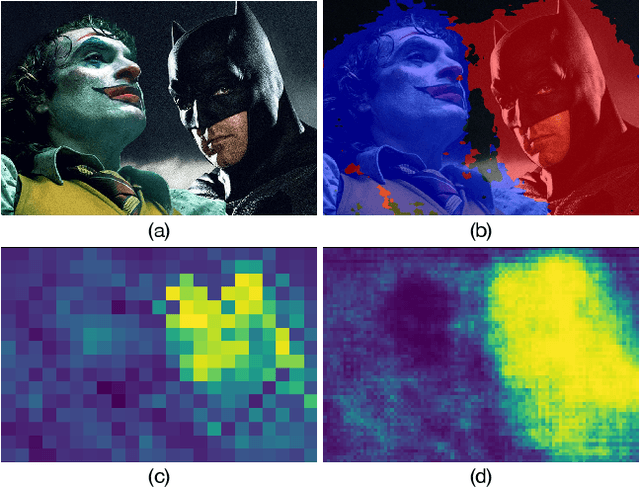
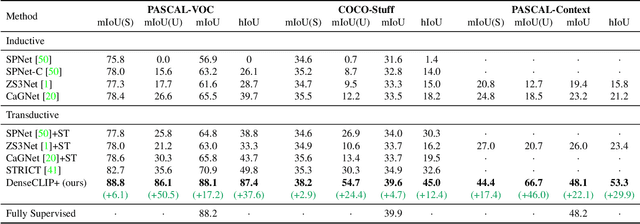
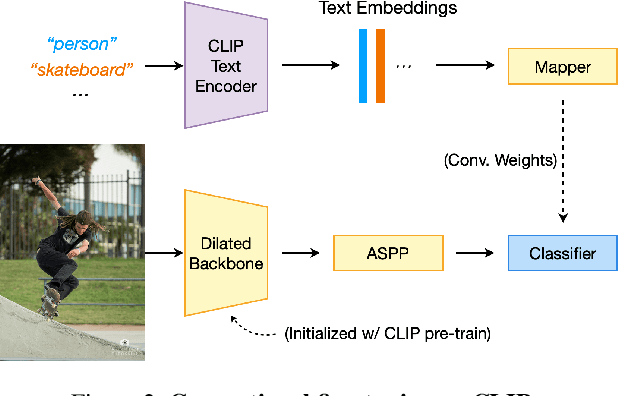

Contrastive Language-Image Pre-training (CLIP) has made a remarkable breakthrough in open-vocabulary zero-shot image recognition. Many recent studies leverage the pre-trained CLIP models for image-level classification and manipulation. In this paper, we further explore the potentials of CLIP for pixel-level dense prediction, specifically in semantic segmentation. Our method, DenseCLIP, in the absence of annotations and fine-tuning, yields reasonable segmentation results on open concepts across various datasets. By adding pseudo labeling and self-training, DenseCLIP+ surpasses SOTA transductive zero-shot semantic segmentation methods by large margins, e.g., mIoUs of unseen classes on PASCAL VOC/PASCAL Context/COCO Stuff are improved from 35.6/20.7/30.3 to 86.1/66.7/54.7. We also test the robustness of DenseCLIP under input corruption and evaluate its capability in discriminating fine-grained objects and novel concepts. Our finding suggests that DenseCLIP can serve as a new reliable source of supervision for dense prediction tasks to achieve annotation-free segmentation.