 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemo2Vec: Learning Region Embedding with Demographic Information
Paper and Code
Sep 25, 2024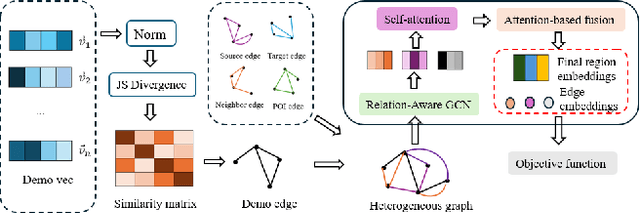
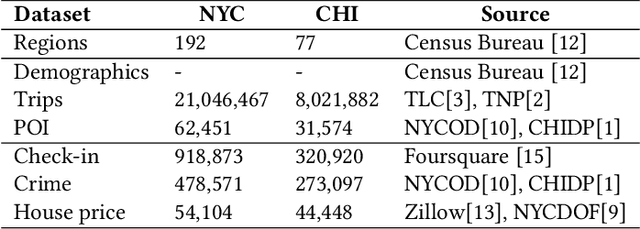

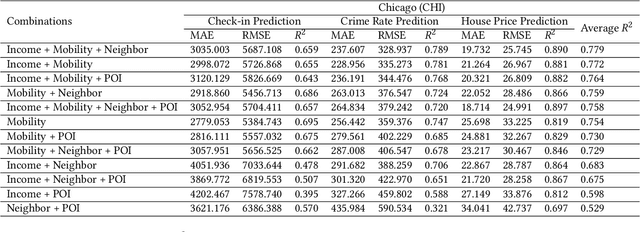
Demographic data, such as income, education level, and employment rate, contain valuable information of urban regions, yet few studies have integrated demographic information to generate region embedding. In this study, we show how the simple and easy-to-access demographic data can improve the quality of state-of-the-art region embedding and provide better predictive performances in urban areas across three common urban tasks, namely check-in prediction, crime rate prediction, and house price prediction. We find that existing pre-train methods based on KL divergence are potentially biased towards mobility information and propose to use Jenson-Shannon divergence as a more appropriate loss function for multi-view representation learning. Experimental results from both New York and Chicago show that mobility + income is the best pre-train data combination, providing up to 10.22\% better predictive performances than existing models. Considering that mobility big data can be hardly accessible in many developing cities, we suggest geographic proximity + income to be a simple but effective data combination for region embedding pre-training.