 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep neural network or dermatologist?
Paper and Code

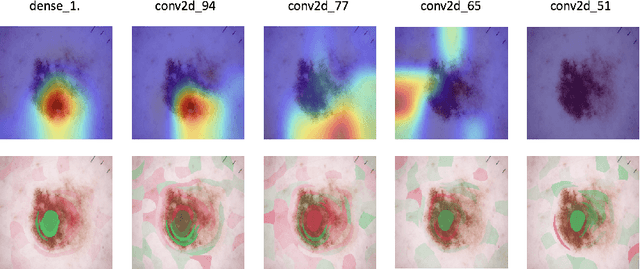

Deep learning techniques have proven high accuracy for identifying melanoma in digitised dermoscopic images. A strength is that these methods are not constrained by features that are pre-defined by human semantics. A down-side is that it is difficult to understand the rationale of the model predictions and to identify potential failure modes. This is a major barrier to adoption of deep learning in clinical practice. In this paper we ask if two existing local interpretability methods, Grad-CAM and Kernel SHAP, can shed light on convolutional neural networks trained in the context of melanoma detection. Our contributions are (i) we first explore the domain space via a reproducible, end-to-end learning framework that creates a suite of 30 models, all trained on a publicly available data set (HAM10000), (ii) we next explore the reliability of GradCAM and Kernel SHAP in this context via some basic sanity check experiments (iii) finally, we investigate a random selection of models from our suite using GradCAM and Kernel SHAP. We show that despite high accuracy, the models will occasionally assign importance to features that are not relevant to the diagnostic task. We also show that models of similar accuracy will produce different explanations as measured by these methods. This work represents first steps in bridging the gap between model accuracy and interpretability in the domain of skin cancer classification.