 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Generative Models for Decision-Making and Control
Paper and Code
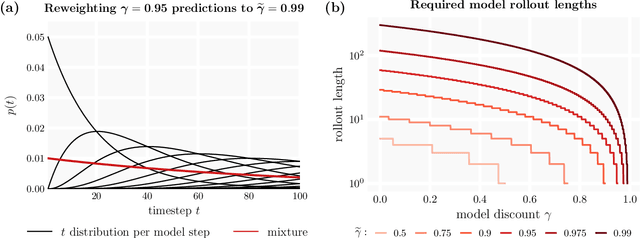
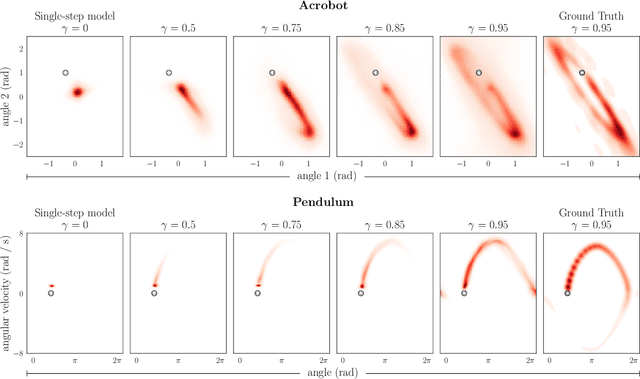
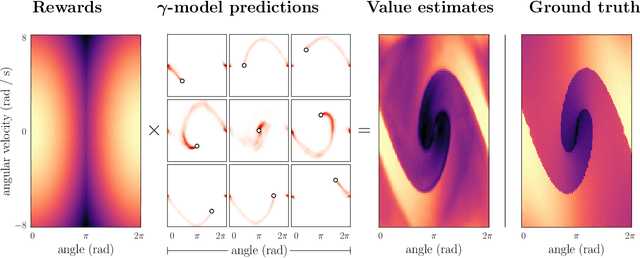
Deep model-based reinforcement learning methods offer a conceptually simple approach to the decision-making and control problem: use learning for the purpose of estimating an approximate dynamics model, and offload the rest of the work to classical trajectory optimization. However, this combination has a number of empirical shortcomings, limiting the usefulness of model-based methods in practice. The dual purpose of this thesis is to study the reasons for these shortcomings and to propose solutions for the uncovered problems. Along the way, we highlight how inference techniques from the contemporary generative modeling toolbox, including beam search, classifier-guided sampling, and image inpainting, can be reinterpreted as viable planning strategies for reinforcement learning problems.