 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Gaussian Covariance Network
Paper and Code
Oct 27, 2017

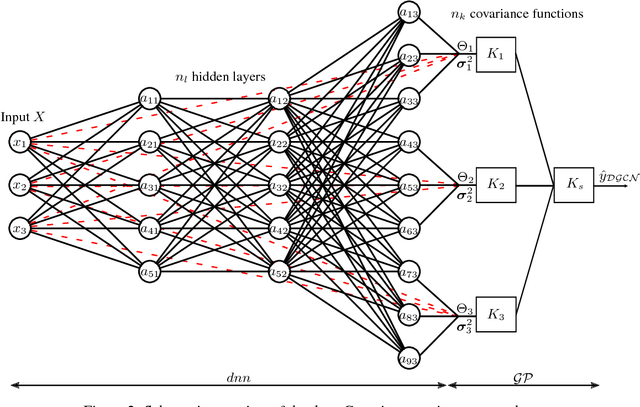

The correlation length-scale next to the noise variance are the most used hyperparameters for the Gaussian processes. Typically, stationary covariance functions are used, which are only dependent on the distances between input points and thus invariant to the translations in the input space. The optimization of the hyperparameters is commonly done by maximizing the log marginal likelihood. This works quite well, if the distances are uniform distributed. In the case of a locally adapted or even sparse input space, the prediction of a test point can be worse dependent of its position. A possible solution to this, is the usage of a non-stationary covariance function, where the hyperparameters are calculated by a deep neural network. So that the correlation length scales and possibly the noise variance are dependent on the test point. Furthermore, different types of covariance functions are trained simultaneously, so that the Gaussian process prediction is an additive overlay of different covariance matrices. The right covariance functions combination and its hyperparameters are learned by the deep neural network. Additional, the Gaussian process will be able to be trained by batches or online and so it can handle arbitrarily large data sets. We call this framework Deep Gaussian Covariance Network (DGCP). There are also further extensions to this framework possible, for example sequentially dependent problems like time series or the local mixture of experts. The basic framework and some extension possibilities will be presented in this work. Moreover, a comparison to some recent state of the art surrogate model methods will be performed, also for a time dependent problem.