 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Diacritization: Efficient Hierarchical Recurrence for Improved Arabic Diacritization
Paper and Code
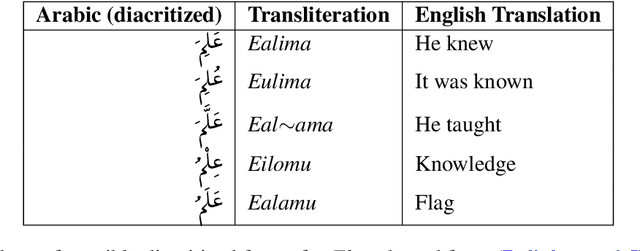
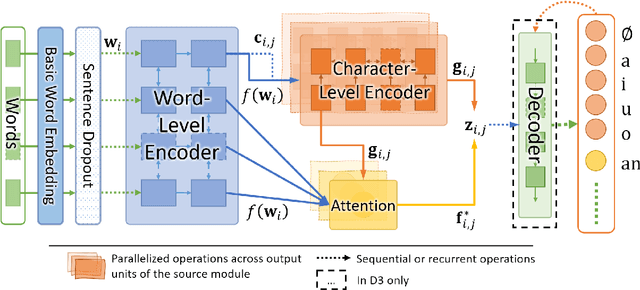

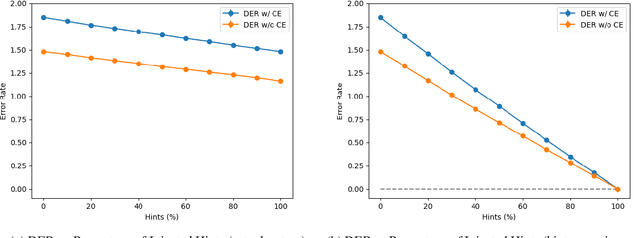
We propose a novel architecture for labelling character sequences that achieves state-of-the-art results on the Tashkeela Arabic diacritization benchmark. The core is a two-level recurrence hierarchy that operates on the word and character levels separately---enabling faster training and inference than comparable traditional models. A cross-level attention module further connects the two, and opens the door for network interpretability. The task module is a softmax classifier that enumerates valid combinations of diacritics. This architecture can be extended with a recurrent decoder that optionally accepts priors from partially diacritized text, which improves results. We employ extra tricks such as sentence dropout and majority voting to further boost the final result. Our best model achieves a WER of 5.34%, outperforming the previous state-of-the-art with a 30.56% relative error reduction.