 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision-based Black-box Attack Against Vision Transformers via Patch-wise Adversarial Removal
Paper and Code
Dec 07, 2021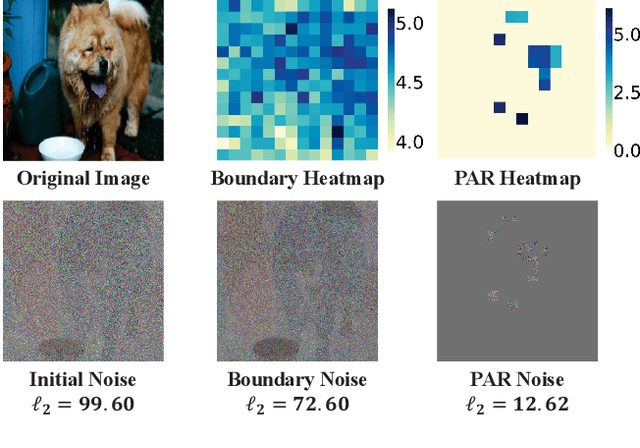



Vision transformers (ViTs) have demonstrated impressive performance and stronger adversarial robustness compared to Deep Convolutional Neural Networks (CNNs). On the one hand, ViTs' focus on global interaction between individual patches reduces the local noise sensitivity of images. On the other hand, the existing decision-based attacks for CNNs ignore the difference in noise sensitivity between different regions of the image, which affects the efficiency of noise compression. Therefore, validating the black-box adversarial robustness of ViTs when the target model can only be queried still remains a challenging problem. In this paper, we propose a new decision-based black-box attack against ViTs termed Patch-wise Adversarial Removal (PAR). PAR divides images into patches through a coarse-to-fine search process and compresses the noise on each patch separately. PAR records the noise magnitude and noise sensitivity of each patch and selects the patch with the highest query value for noise compression. In addition, PAR can be used as a noise initialization method for other decision-based attacks to improve the noise compression efficiency on both ViTs and CNNs without introducing additional calculations. Extensive experiments on ImageNet-21k, ILSVRC-2012, and Tiny-Imagenet datasets demonstrate that PAR achieves a much lower magnitude of perturbation on average with the same number of queries.