 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycle-StarNet: Bridging the gap between theory and data by leveraging large datasets
Paper and Code
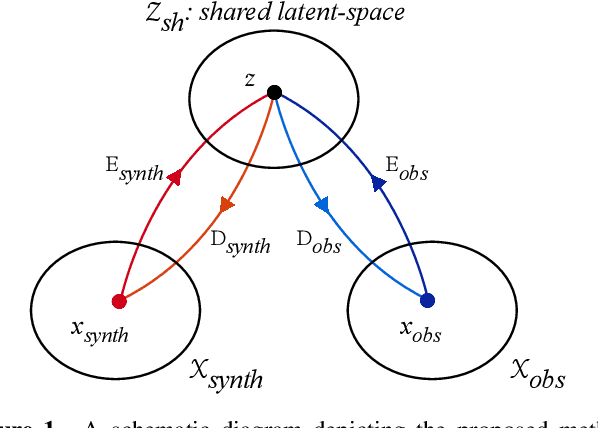

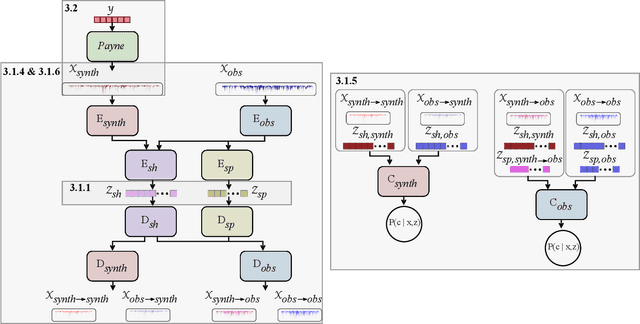
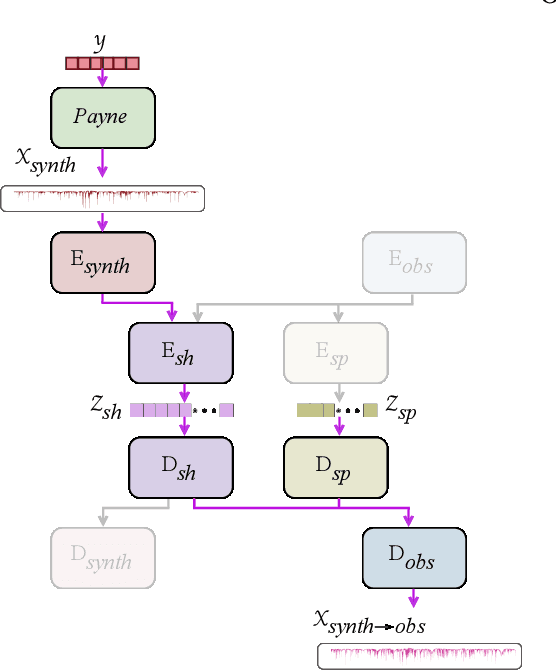
Spectroscopy provides an immense amount of information on stellar objects, and this field continues to grow with recent developments in multi-object data acquisition and rapid data analysis techniques. Current automated methods for analyzing spectra are either (a) data-driven models, which require large amounts of data with prior knowledge of stellar parameters and elemental abundances, or (b) based on theoretical synthetic models that are susceptible to the gap between theory and practice. In this study, we present a hybrid generative domain adaptation method to turn simulated stellar spectra into realistic spectra, learning from the large spectroscopic surveys. We use a neural network to emulate computationally expensive stellar spectra simulations, and then train a separate unsupervised domain-adaptation network that learns to relate the generated synthetic spectra to observational spectra. Consequently, the network essentially produces data-driven models without the need for a labeled training set. As a proof of concept, two case studies are presented. The first of which is the auto-calibration of synthetic models without using any standard stars. To accomplish this, synthetic models are morphed into spectra that resemble observations, thereby reducing the gap between theory and observations. The second case study is the identification of the elemental source of missing spectral lines in the synthetic modelling. These sources are predicted by interpreting the differences between the domain-adapted and original spectral models. To test our ability to identify missing lines, we use a mock dataset and show that, even with noisy observations, absorption lines can be recovered when they are absent in one of the domains. While we focus on spectral analyses in this study, this method can be applied to other fields, which use large data sets and are currently limited by modelling accuracy.