 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Lingual Transfer for Distantly Supervised and Low-resources Indonesian NER
Paper and Code
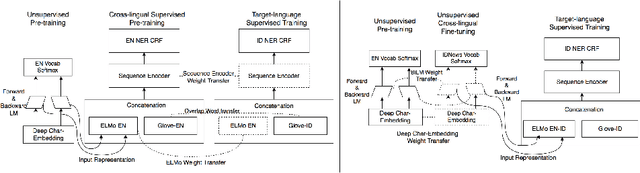



Manually annotated corpora for low-resource languages are usually small in quantity (gold), or large but distantly supervised (silver). Inspired by recent progress of injecting pre-trained language model (LM) on many Natural Language Processing (NLP) task, we proposed to fine-tune pre-trained language model from high-resources languages to low-resources languages to improve the performance of both scenarios. Our empirical experiment demonstrates significant improvement when fine-tuning pre-trained language model in cross-lingual transfer scenarios for small gold corpus and competitive results in large silver compare to supervised cross-lingual transfer, which will be useful when there is no parallel annotation in the same task to begin. We compare our proposed method of cross-lingual transfer using pre-trained LM to different sources of transfer such as mono-lingual LM and Part-of-Speech tagging (POS) in the downstream task of both large silver and small gold NER dataset by exploiting character-level input of bi-directional language model task.