 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritical Questions Generation: Motivation and Challenges
Paper and Code

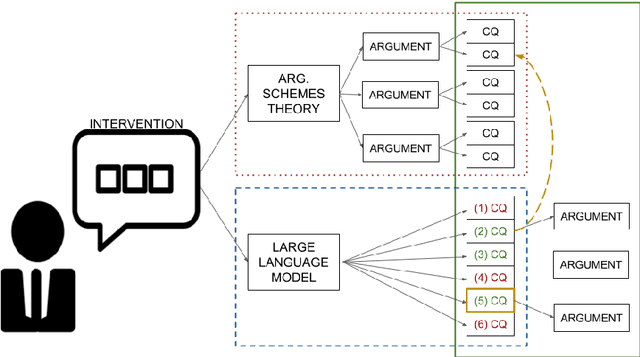


The development of Large Language Models (LLMs) has brought impressive performances on mitigation strategies against misinformation, such as counterargument generation. However, LLMs are still seriously hindered by outdated knowledge and by their tendency to generate hallucinated content. In order to circumvent these issues, we propose a new task, namely, Critical Questions Generation, consisting of processing an argumentative text to generate the critical questions (CQs) raised by it. In argumentation theory CQs are tools designed to lay bare the blind spots of an argument by pointing at the information it could be missing. Thus, instead of trying to deploy LLMs to produce knowledgeable and relevant counterarguments, we use them to question arguments, without requiring any external knowledge. Research on CQs Generation using LLMs requires a reference dataset for large scale experimentation. Thus, in this work we investigate two complementary methods to create such a resource: (i) instantiating CQs templates as defined by Walton's argumentation theory and (ii), using LLMs as CQs generators. By doing so, we contribute with a procedure to establish what is a valid CQ and conclude that, while LLMs are reasonable CQ generators, they still have a wide margin for improvement in this task.