 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritical Evaluation of LOCO dataset with Machine Learning
Paper and Code
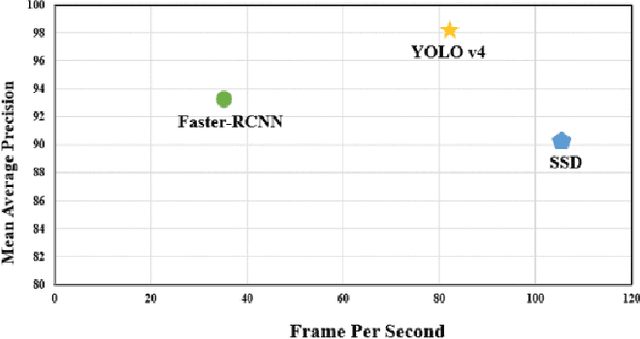



Purpose: Object detection is rapidly evolving through machine learning technology in automation systems. Well prepared data is necessary to train the algorithms. Accordingly, the objective of this paper is to describe a re-evaluation of the so-called Logistics Objects in Context (LOCO) dataset, which is the first dataset for object detection in the field of intralogistics. Methodology: We use an experimental research approach with three steps to evaluate the LOCO dataset. Firstly, the images on GitHub were analyzed to understand the dataset better. Secondly, Google Drive Cloud was used for training purposes to revisit the algorithmic implementation and training. Lastly, the LOCO dataset was examined, if it is possible to achieve the same training results in comparison to the original publications. Findings: The mean average precision, a common benchmark in object detection, achieved in our study was 64.54%, and shows a significant increase from the initial study of the LOCO authors, achieving 41%. However, improvement potential is seen specifically within object types of forklifts and pallet truck. Originality: This paper presents the first critical replication study of the LOCO dataset for object detection in intralogistics. It shows that the training with better hyperparameters based on LOCO can even achieve a higher accuracy than presented in the original publication. However, there is also further room for improving the LOCO dataset.