 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive String Representation Learning using Synthetic Data
Paper and Code
Oct 08, 2021
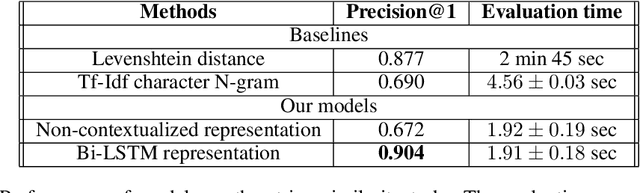
String representation Learning (SRL) is an important task in the field of Natural Language Processing, but it remains under-explored. The goal of SRL is to learn dense and low-dimensional vectors (or embeddings) for encoding character sequences. The learned representation from this task can be used in many downstream application tasks such as string similarity matching or lexical normalization. In this paper, we propose a new method for to train a SRL model by only using synthetic data. Our approach makes use of Contrastive Learning in order to maximize similarity between related strings while minimizing it for unrelated strings. We demonstrate the effectiveness of our approach by evaluating the learned representation on the task of string similarity matching. Codes, data and pretrained models will be made publicly available.