 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning with Dirichlet Generative-based Rehearsal
Paper and Code
Sep 13, 2023
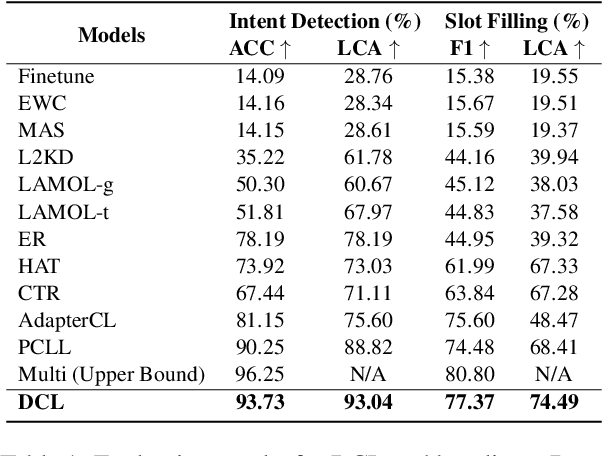
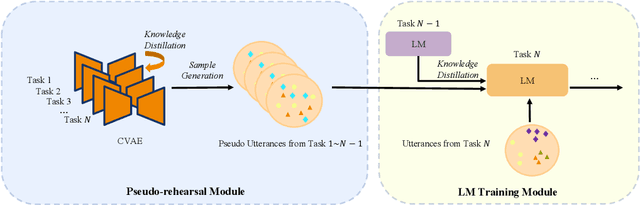
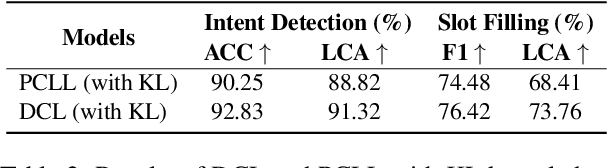
Recent advancements in data-driven task-oriented dialogue systems (ToDs) struggle with incremental learning due to computational constraints and time-consuming issues. Continual Learning (CL) attempts to solve this by avoiding intensive pre-training, but it faces the problem of catastrophic forgetting (CF). While generative-based rehearsal CL methods have made significant strides, generating pseudo samples that accurately reflect the underlying task-specific distribution is still a challenge. In this paper, we present Dirichlet Continual Learning (DCL), a novel generative-based rehearsal strategy for CL. Unlike the traditionally used Gaussian latent variable in the Conditional Variational Autoencoder (CVAE), DCL leverages the flexibility and versatility of the Dirichlet distribution to model the latent prior variable. This enables it to efficiently capture sentence-level features of previous tasks and effectively guide the generation of pseudo samples. In addition, we introduce Jensen-Shannon Knowledge Distillation (JSKD), a robust logit-based knowledge distillation method that enhances knowledge transfer during pseudo sample generation. Our experiments confirm the efficacy of our approach in both intent detection and slot-filling tasks, outperforming state-of-the-art methods.