 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext based Roman-Urdu to Urdu Script Transliteration System
Paper and Code
Sep 29, 2021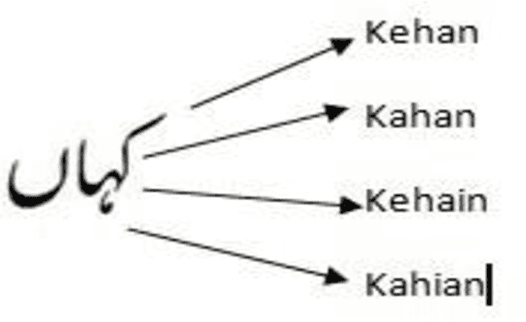

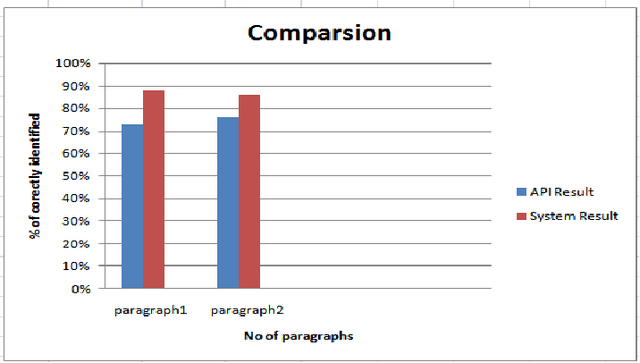
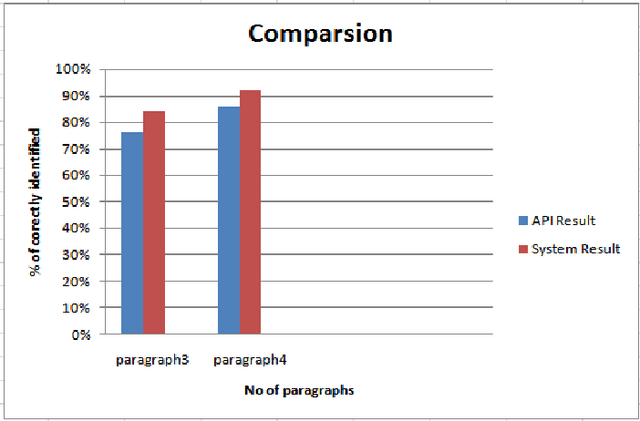
Now a day computer is necessary for human being and it is very useful in many fields like search engine, text processing, short messaging services, voice chatting and text recognition. Since last many years there are many tools and techniques that have been developed to support the writing of language script. Most of the Asian languages like Arabic, Urdu, Persian, Chains and Korean are written in Roman alphabets. Roman alphabets are the most commonly used for transliteration of languages, which have non-Latin scripts. For writing Urdu characters as an input, there are many layouts which are already exist. Mostly Urdu speaker prefer to use Roman-Urdu for different applications, because mostly user is not familiar with Urdu language keyboard. The objective of this work is to improve the context base transliteration of Roman-Urdu to Urdu script. In this paper, we propose an algorithm which effectively solve the transliteration issues. The algorithm work like, convert the encoding roman words into the words in the standard Urdu script and match it with the lexicon. If match found, then display the word in the text editor. The highest frequency words are displayed if more than one match found in the lexicon. Display the first encoded and converted instance and set it to the default if there is not a single instance of the match is found and then adjust the given ambiguous word to their desire location according to their context. The outcome of this algorithm proved the efficiency and significance as compare to other models and algorithms which work for transliteration of Raman-Urdu to Urdu on context.