Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressed imitation learning
Paper and Code
Sep 18, 2020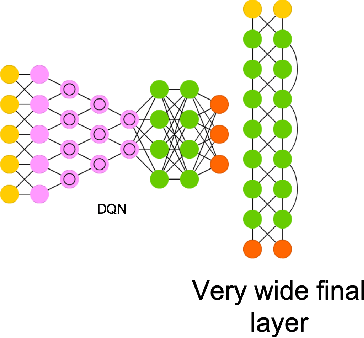
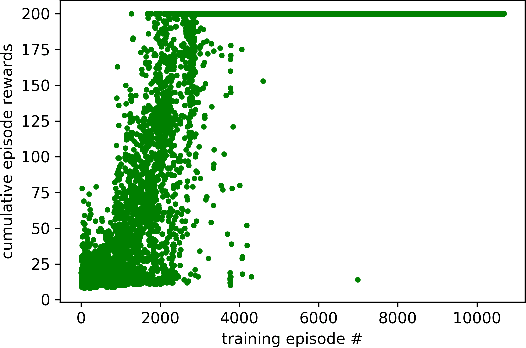
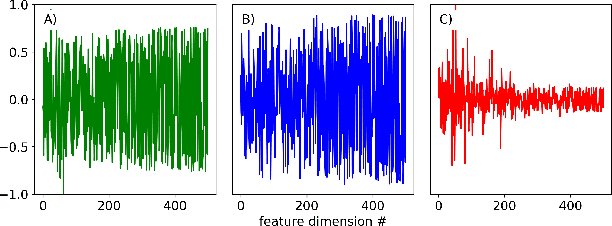
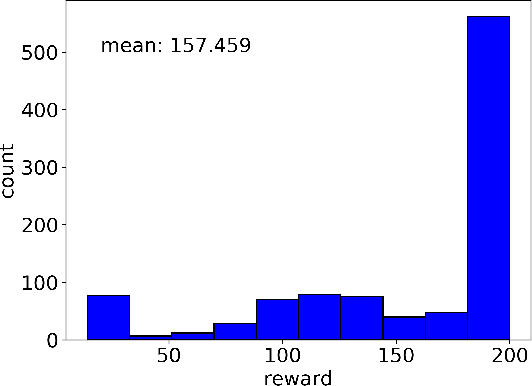
In analogy to compressed sensing, which allows sample-efficient signal reconstruction given prior knowledge of its sparsity in frequency domain, we propose to utilize policy simplicity (Occam's Razor) as a prior to enable sample-efficient imitation learning. We first demonstrated the feasibility of this scheme on linear case where state-value function can be sampled directly. We also extended the scheme to scenarios where only actions are visible and scenarios where the policy is obtained from nonlinear network. The method is benchmarked against behavior cloning and results in significantly higher scores with limited expert demonstrations.
View paper on