 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Study of Differentially Private Synthetic Data Algorithms and Evaluation Standards
Paper and Code
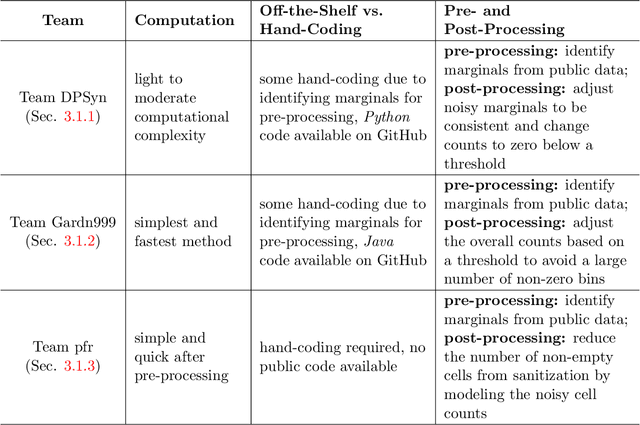
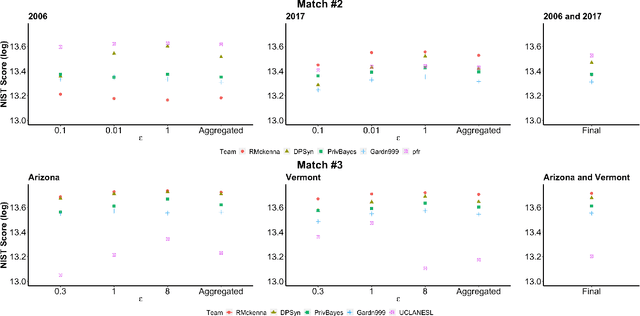
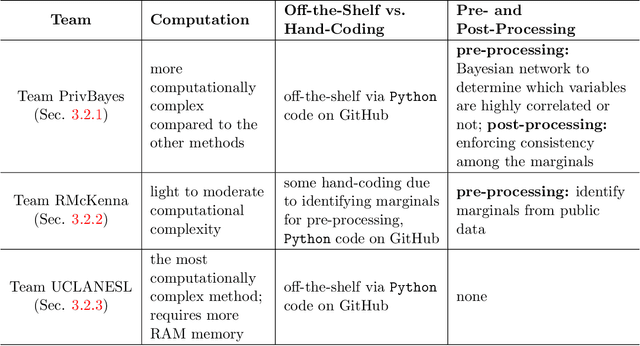
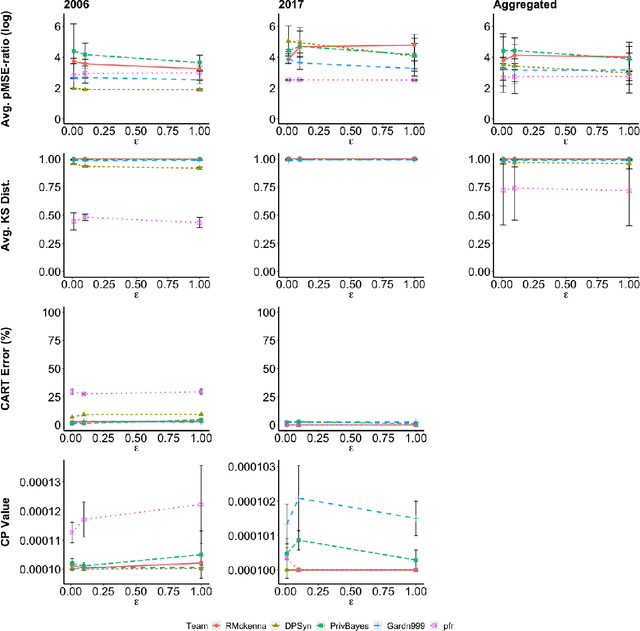
Differentially private synthetic data generation is becoming a popular solution that releases analytically useful data while preserving the privacy of individuals in the data. In order to utilize these algorithms for public policy decisions, policymakers need an accurate understanding of these algorithms' comparative performance. Correspondingly, data practitioners also require standard metrics for evaluating the analytic qualities of the synthetic data. In this paper, we present an in-depth evaluation of several differentially private synthetic data algorithms using the actual differentially private synthetic data sets created by contestants in the recent National Institute of Standards and Technology's (NIST) "Differentially Private Synthetic Data Challenge." We offer both theoretical and practical analyses of these algorithms. We frame the NIST data challenge methods within the broader differentially private synthetic data literature. In addition, we implement two of our own utility metric algorithms on the differentially private synthetic data and compare these metrics' results to the NIST data challenge outcome. Our comparative assessment of the differentially private data synthesis methods and the quality metrics shows the relative usefulness, general strengths and weaknesses, preferred choices of algorithms and metrics. Finally we give implications of our evaluation for policymakers seeking to implement differentially private synthetic data algorithms on future data products.