 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommonAccent: Exploring Large Acoustic Pretrained Models for Accent Classification Based on Common Voice
Paper and Code
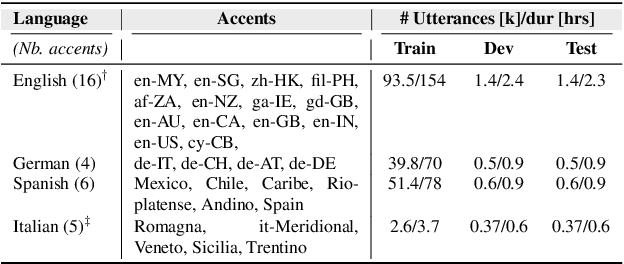
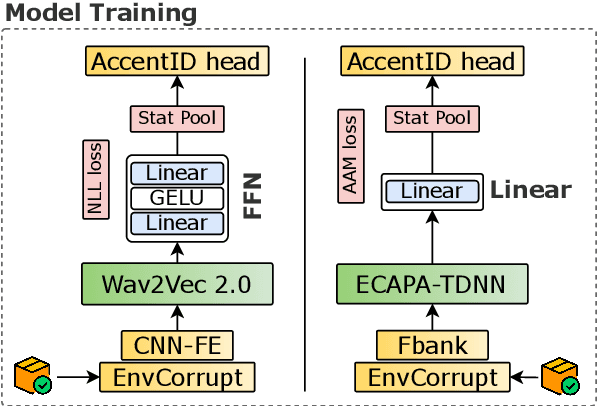
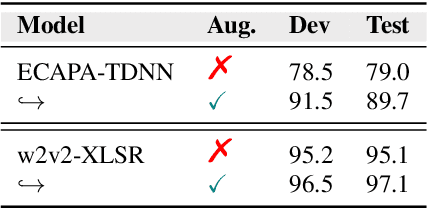
Despite the recent advancements in Automatic Speech Recognition (ASR), the recognition of accented speech still remains a dominant problem. In order to create more inclusive ASR systems, research has shown that the integration of accent information, as part of a larger ASR framework, can lead to the mitigation of accented speech errors. We address multilingual accent classification through the ECAPA-TDNN and Wav2Vec 2.0/XLSR architectures which have been proven to perform well on a variety of speech-related downstream tasks. We introduce a simple-to-follow recipe aligned to the SpeechBrain toolkit for accent classification based on Common Voice 7.0 (English) and Common Voice 11.0 (Italian, German, and Spanish). Furthermore, we establish new state-of-the-art for English accent classification with as high as 95% accuracy. We also study the internal categorization of the Wav2Vev 2.0 embeddings through t-SNE, noting that there is a level of clustering based on phonological similarity. (Our recipe is open-source in the SpeechBrain toolkit, see: https://github.com/speechbrain/speechbrain/tree/develop/recipes)