 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombination of Time-domain, Frequency-domain, and Cepstral-domain Acoustic Features for Speech Commands Classification
Paper and Code
Mar 30, 2022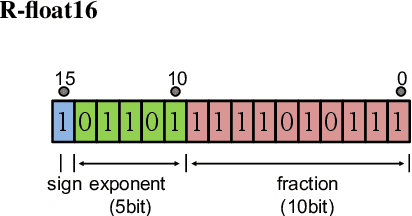
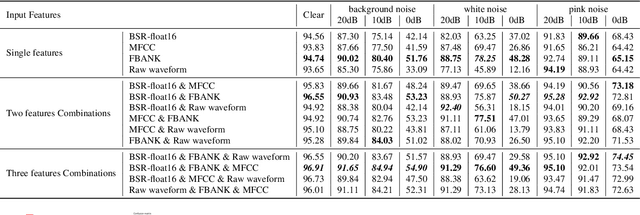
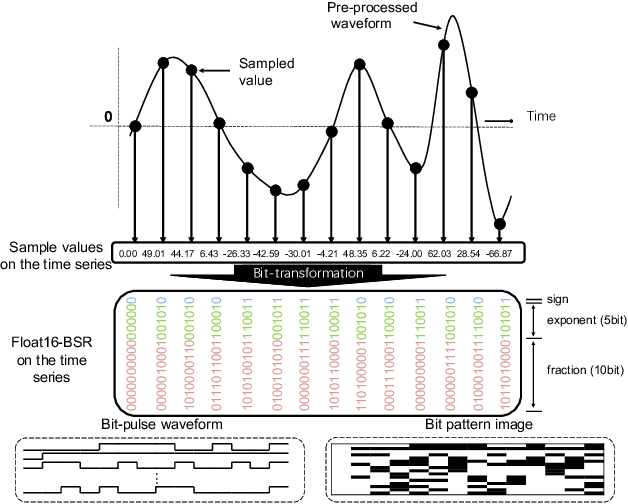
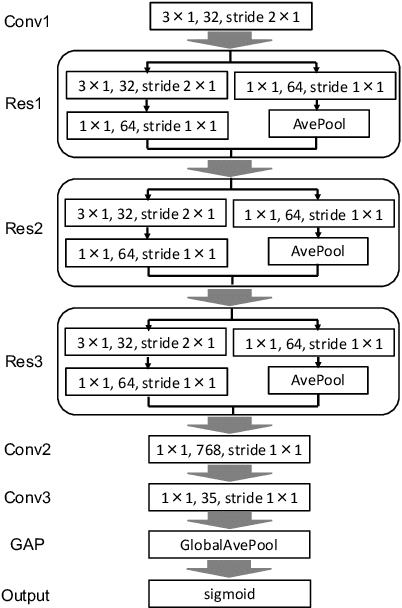
In speech-related classification tasks, frequency-domain acoustic features such as logarithmic Mel-filter bank coefficients (FBANK) and cepstral-domain acoustic features such as Mel-frequency cepstral coefficients (MFCC) are often used. However, time-domain features perform more effectively in some sound classification tasks which contain non-vocal or weakly speech-related sounds. We previously proposed a feature called bit sequence representation (BSR), which is a time-domain binary acoustic feature based on the raw waveform. Compared with MFCC, BSR performed better in environmental sound detection and showed comparable accuracy performance in limited-vocabulary speech recognition tasks. In this paper, we propose a novel improvement BSR feature called BSR-float16 to represent floating-point values more precisely. We experimentally demonstrated the complementarity among time-domain, frequency-domain, and cepstral-domain features using a dataset called Speech Commands proposed by Google. Therefore, we used a simple back-end score fusion method to improve the final classification accuracy. The fusion results also showed better noise robustness.