 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaboratively adding new knowledge to an LLM
Paper and Code
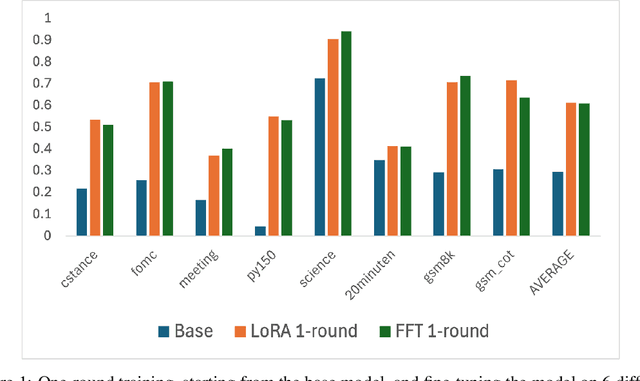
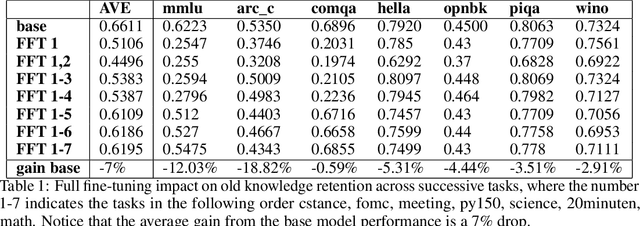
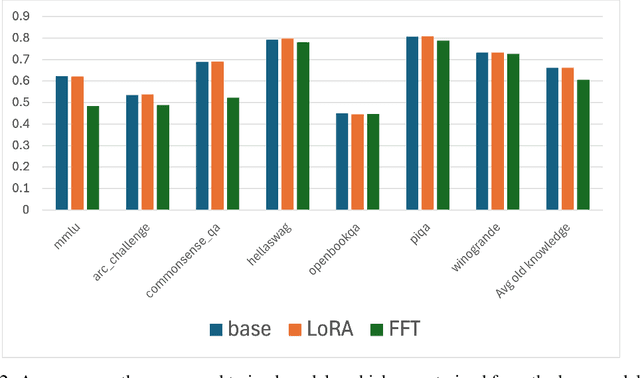

We address the question of how to successively add new knowledge to an LLM whilst retaining previously-added knowledge. We consider two settings, semi-cooperative and fully-cooperative. Overall, LoRA performs better in most cases than full-fine tuning of all parameters when both new knowledge acquisition and retention of old, including recent, knowledge are taken into account. In the semi-cooperative setting, where datasets are not available after training, MOE mixing, model merging, and LoRA-based orthogonal subspace sequential learning, using a small weight on the orthogonality term, perform well. In the fully-cooperative setting where datasets remain available, joint training and sequential training with replay are both effective approaches with LoRA training generally preferable to full fine-tuning. The codes needed to reproduce the results are provided in an open source repository.