 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCocktail HuBERT: Generalized Self-Supervised Pre-training for Mixture and Single-Source Speech
Paper and Code
Mar 20, 2023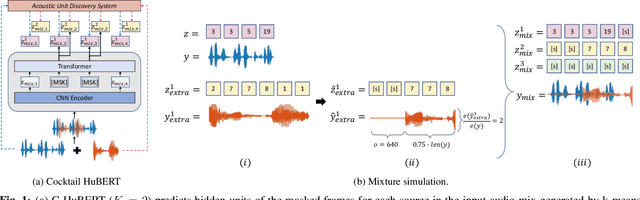
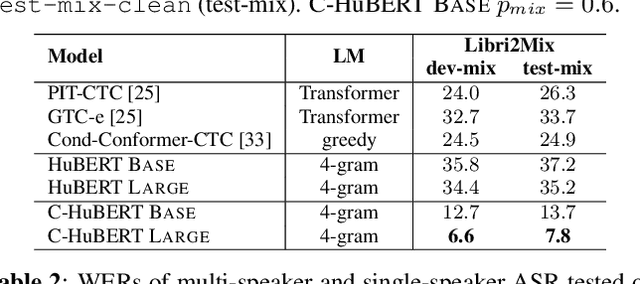
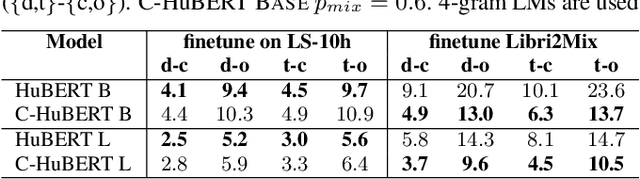
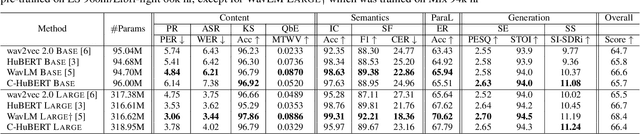
Self-supervised learning leverages unlabeled data effectively, improving label efficiency and generalization to domains without labeled data. While recent work has studied generalization to more acoustic/linguistic domains, languages, and modalities, these investigations are limited to single-source speech with one primary speaker in the recording. This paper presents Cocktail HuBERT, a self-supervised learning framework that generalizes to mixture speech using a masked pseudo source separation objective. This objective encourages the model to identify the number of sources, separate and understand the context, and infer the content of masked regions represented as discovered units. Cocktail HuBERT outperforms state-of-the-art results with 69% lower WER on multi-speaker ASR, 31% lower DER on diarization, and is competitive on single- and multi-speaker tasks from SUPERB.