Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-To-Fine And Cross-Lingual ASR Transfer
Paper and Code
Sep 02, 2021

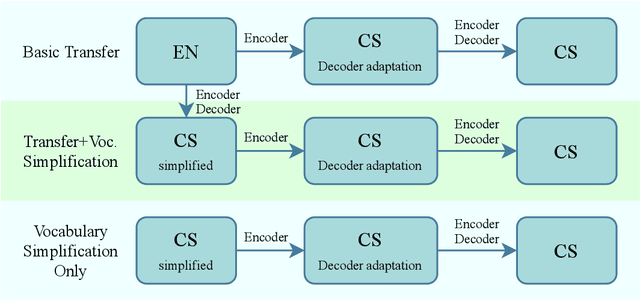

End-to-end neural automatic speech recognition systems achieved recently state-of-the-art results, but they require large datasets and extensive computing resources. Transfer learning has been proposed to overcome these difficulties even across languages, e.g., German ASR trained from an English model. We experiment with much less related languages, reusing an English model for Czech ASR. To simplify the transfer, we propose to use an intermediate alphabet, Czech without accents, and document that it is a highly effective strategy. The technique is also useful on Czech data alone, in the style of coarse-to-fine training. We achieve substantial eductions in training time as well as word error rate (WER).
* Accepted to ITAT WAFNL
View paper on