 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering-based Automatic Construction of Legal Entity Knowledge Base from Contracts
Paper and Code
Dec 07, 2020
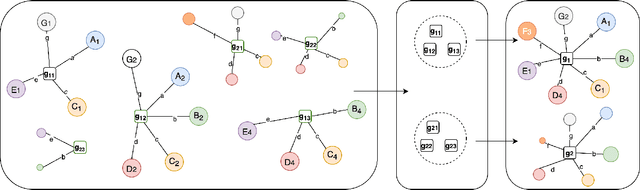

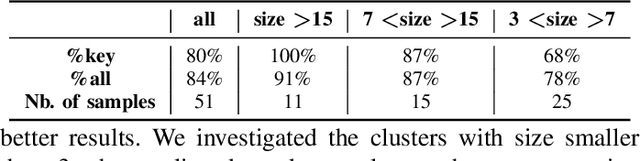
In contract analysis and contract automation, a knowledge base (KB) of legal entities is fundamental for performing tasks such as contract verification, contract generation and contract analytic. However, such a KB does not always exist nor can be produced in a short time. In this paper, we propose a clustering-based approach to automatically generate a reliable knowledge base of legal entities from given contracts without any supplemental references. The proposed method is robust to different types of errors brought by pre-processing such as Optical Character Recognition (OCR) and Named Entity Recognition (NER), as well as editing errors such as typos. We evaluate our method on a dataset that consists of 800 real contracts with various qualities from 15 clients. Compared to the collected ground-truth data, our method is able to recall 84\% of the knowledge.