 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCleansing Jewel: A Neural Spelling Correction Model Built On Google OCR-ed Tibetan Manuscripts
Paper and Code
Apr 07, 2023

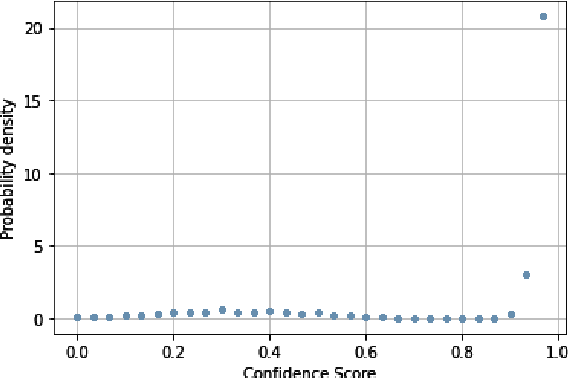

Scholars in the humanities rely heavily on ancient manuscripts to study history, religion, and socio-political structures in the past. Many efforts have been devoted to digitizing these precious manuscripts using OCR technology, but most manuscripts were blemished over the centuries so that an Optical Character Recognition (OCR) program cannot be expected to capture faded graphs and stains on pages. This work presents a neural spelling correction model built on Google OCR-ed Tibetan Manuscripts to auto-correct OCR-ed noisy output. This paper is divided into four sections: dataset, model architecture, training and analysis. First, we feature-engineered our raw Tibetan etext corpus into two sets of structured data frames -- a set of paired toy data and a set of paired real data. Then, we implemented a Confidence Score mechanism into the Transformer architecture to perform spelling correction tasks. According to the Loss and Character Error Rate, our Transformer + Confidence score mechanism architecture proves to be superior to Transformer, LSTM-2-LSTM and GRU-2-GRU architectures. Finally, to examine the robustness of our model, we analyzed erroneous tokens, visualized Attention and Self-Attention heatmaps in our model.